

教養としてのAI講義:トランスフォーマーと自己教師あり学習

最近の目覚ましいAIの発展は、どのような技術に支えられているのだろうか?ビジネスへ効果的にAI技術を取り入れるためにも、その裏でどのような技術が使われているかを理解することは、ビジネスパーソンにとっても必要だ。
たとえば、AIの第一人者である東京大学の松尾豊氏の講演内容が書き起こされた次のスライドでは、ChatGPTのような生成AIを支える大規模言語モデル(LLM)に関する説明が簡潔にまとめられている。
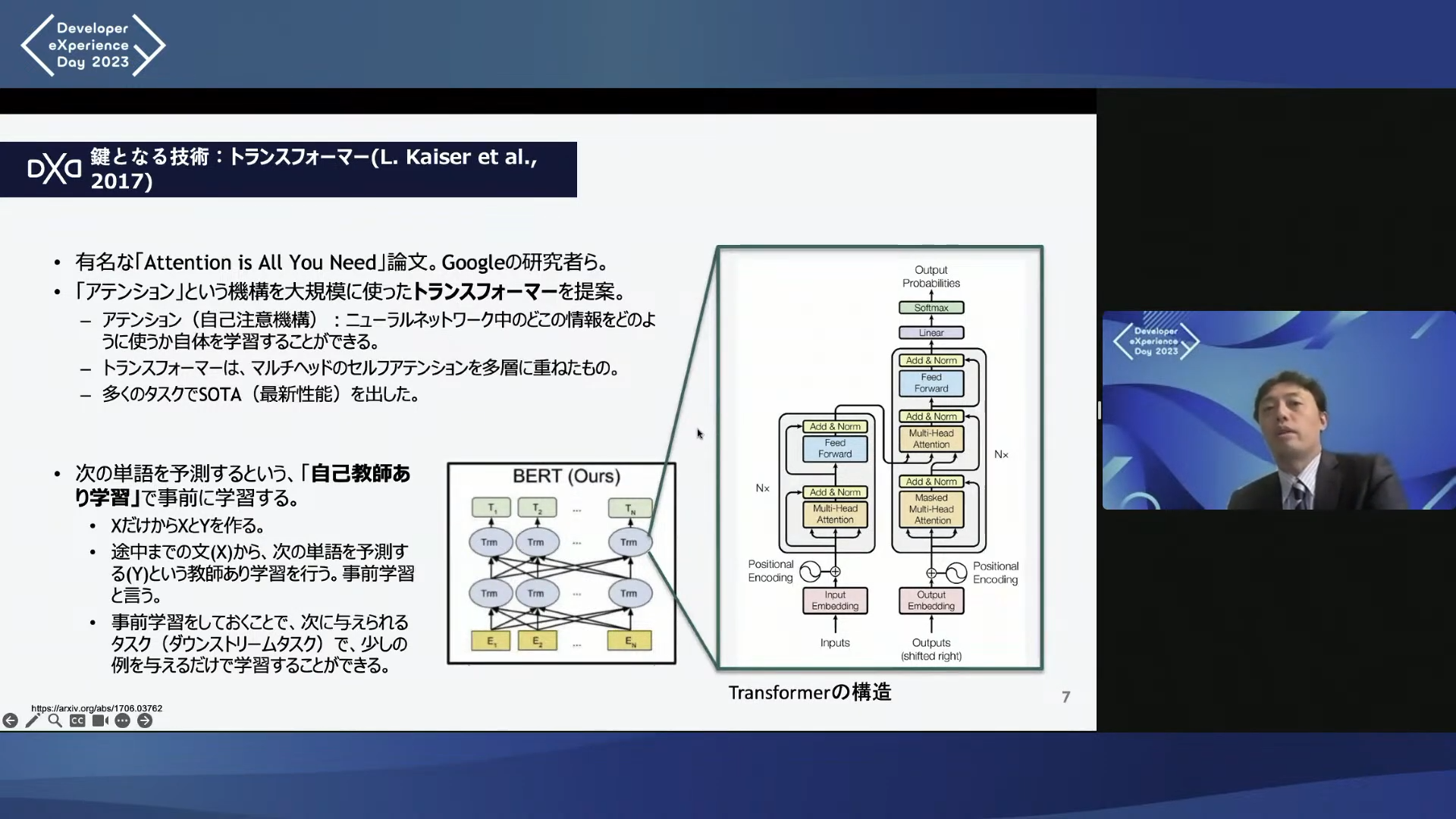
そこで、大規模言語モデルに関するコアな技術である「トランスフォーマー」と「自己教師あり学習」そして、「人間からのフィードバックに基づく強化学習」について、上述の松尾さんが解説している内容をさらに噛み砕き補足しながら、前半と後半にわたって分かりやすく解説する。まず、1つ目のこの記事では、トランスフォーマーと自己教師あり学習について解説する。
トランスフォーマー:単語のつながりと多様な視点からの文章理解
トランスフォーマーは、現在のAI技術の盛り上がりを牽いんするディープラーニング技術の一つである。ディープラーニングは、人間の脳の構造を模倣した多層ネットワークによって、複雑なパターンを捉えることができるコンピュータモデルだ。ディープラーニングは、画像認識や感情分析などの複雑なタスクを精度良くこなし、ビジネスへの応用も進んでいる。
しかし、自然言語処理と呼ばれる、人間の言葉を扱うタスクの精度は伸び悩んでいた。自然言語処理では、文の構造や文脈を理解するための高度な能力が求められるが、従来のディープラーニングではこれらの要素を十分に捉えることができなかったからだ。
たとえば、次のような文があるとする。
「日本の首都は東京です。東京には多くの観光スポットがあります。」
この文章に対して、「多くの観光スポットがある都市はどこですか?」という質問がある場合、答えは「東京」となる。だが、トランスフォーマー以前のモデルでは、「日本」という間違った答えを返すことがあった。これは、従来のモデルが「観光スポット」と「東京」が強く関連していることや、「東京」が「都市」であるという文脈やを正確に把握できなかったためである。
この問題を解決するために、新たなディープラーニングモデルとして登場したのが「トランスフォーマー」だ。2017年にGoogleの研究チームによって発表された論文『Attention is All You Need』で提唱された。
トランスフォーマーで提案されている、「自己注意(Self-Attention)」と「マルチヘッド(Multi-head self attention)」2つの仕組みによって、文章の構造や文脈の理解が飛躍的に向上することになった。

自己注意:文章中の単語間のつながりを捉える
自己注意は、文章内の各単語がお互いにどのように関連しているかを捉え、その関係の強さを「重み」として表現し、学習する。この重みは、単語間の関連性の強さを数値で示したのもで、文脈に応じて単語間の関係の重要性を判断する。
たとえば、「日本の首都は東京です。」という文の場合、単語間の重みは「日本」と「首都」の間、さらには「首都」と「東京」の間で大きくなる。一方で、「首都」と「です」や「。」の間の重みは小さくなる。これによって、文脈に基づいた単語間のつながりをより適切に捉えられる。
さらに、自己注意の仕組みを使うと、長い文章でも遠く離れた単語間の依存関係も取り出すことができる。「これ」「それ」「あれ」といった指示代名詞やトピックを表す言葉が、文中の遠くに離れた箇所に現れることがよくある。そういった依存関係をうまく捉えられるのだ。

マルチヘッド自己注意:複数の視点から文章を理解する
自己注意は、同じ文章に対して並列的に行われ、同時に複数の「視点」から関係性を捉えることができる。これが「マルチヘッド自己注意(Multi-head self-attention)の仕組みだ。
たとえば、「日本の首都は東京です。東京には多くの観光スポットがあります。」という文章で、マルチヘッドは「東京」と「首都」の間の関係を捉える。この場合、関係は「所属」や「分類」であり、「東京」が「首都」というカテゴリに属していることを示す。さらに、「多く」と「観光スポット」の間の修飾関係も捉えることができる。さまざまな視点から単語間の重みを捉え、文脈を深く理解する。
どのような「視点」を捉えるかは、与えられたデータからトランスフォーマーが自動的に学習する。さまざまなデータでモデルを学習させることで、多様な関係性を学習して表現できるようになるのだ。異なる視点から文を解釈し、それらの視点を組み合わせて文全体の理解を深める。その結果、より豊かな文の解釈へとつながる。
文の構造や文脈を捉えることは、人間でもけっして簡単なタスクではない。だが、トランスフォーマーはその高度な処理能力を駆使して、複雑な文章を解析し、文脈を把握することができるのだ。トランスフォーマーの登場によって、自然言語処理の精度は飛躍的に向上する土台が整った。
自己教師あり学習
最近の目覚ましいAIの発展を支えるもうひとつの技術が、トランスフォーマーを使った「自己教師あり学習(self-surpervised learning)と呼ばれる方法だ。一言でいうと、既存の文章から自動的に予測問題を生成し、答え合わせをしながら自己学習を進める方法だ。
穴埋め問題を解くように自己学習
「自己教師あり学習(self-surpervised learning)とは、一言でいうと、既存の文章から自動的に予測問題を生成し、答え合わせをしながら自己学習を進める方法だ。
そのために、まず入力された文章から一部を隠して穴埋め問題をつくる。
たとえば、「日本の首都は東京です。」という文章からは、以下のような問題をつくる。
・ 「日本の首都は( )です。」
・ 「( )の首都は東京です。」
・ 「日本の( )は東京です。」
次に、( )に入る言葉をモデルに予測させ、答え合わせをしながら学習する。これが自己学習の過程だ。こうした方法を「教師あり」と呼ぶのは、モデルが答えに合うように学習していくからだ。学習が適切に進んでいるかは、モデルが生成した穴埋め問題の結果と、答えが合っているかどうかでチェックする。

穴埋め問題を解くためには、文章の文脈、構造、つながり、背景知識などを学習する必要がある。トランスフォーマーを使うと、これが可能だ。トランスフォーマーはデータを読み込みながら、単語間の関係を捉え、予測確率を高めるように学習する。もし間違っていたら、正しい答えに合うように学習した重みを調整していく。この重みは、単語間の関連性の強さを数値で示したのもで、文脈に応じて単語間の関係の重要性を判断する。この学習を通じて、モデルは穴埋め問題の達人として文章を生成できるようになる。予備校の先生のような試験のプロがさまざまな問題のパターンを瞬時に把握し、正確に回答するように、モデルも学習した知識を利用して穴埋め問題に回答する。
大規模言語モデルへ
さて、トランスフォーマーと自己教師あり学習を使うと、精度がかなりあがるということが、研究者やエンジニアの間で話題となり、AI研究者たちはこぞってこの手法を用いた研究開発を進めていった。そうした開発が盛んに進められる中、トランスフォーマーは従来の言語モデルと異なる特徴があることが明らかとなってきた。
それはモデルを大規模化すればするほど、学習データを増やせば増やすほど、精度が向上するということだ。モデルのサイズとデータ量を増やすことで、文中の単語のニュアンスや文脈の理解が向上する。
「大は小を兼ねる」という言葉があるように、大きなモデルの方が精度が良いのは当然ではないか、と思うかもしれない。だが、トランスフォーマー以前のモデルでは、モデルを大きくするとある時点で性能が頭打ちになる現象が起こっていた。そのため、タスクによって基本的に適切なモデルサイズにすべきだとされていた。特に、パラメータ数が多くモデルのサイズが大きいと、「過学習」に陥いるのだ。
過学習とは、モデルが学習データに過度に適合し、未知のデータに対する性能が低下する現象を指す。これは、たとえば、テストの過去問だけを繰り返し解いている生徒が、本番の試験では対応できない場合に似ている。

しかし、トランスフォーマーは、過学習に陥りにくく、大規模化しても性能が上がり続けた。2018年に発表されたGoogleによるBERTはパラメーター数が3.8億だったが、2年後のOpenAIによるGPT-3は1,750億に増加し、さらに2022年のGoogle PaLMは、5,400億、中国の悟道2.0は1兆7,500億と、モデルは大規模化していくとともに、精度も向上していった。
なぜ大規模化しても精度が上がるつづけるのか。Self-attentionの仕組みのおかげだ、並列的な計算によって大規模なモデルでも学習が比較的に高速に行える、といったことがその理由としてあげられている。しかし、モデルの中で何が起こっているのか、なぜこのようなことが実現できるのかということが、まだはっきり分かっているわけではない。その解明が進められているが、トランスフォーマーと自己教師あり学習によって、これまでとは違うことが起こっているということは確かと言えそうだ。
さて、ここまで「トランスフォーマー」そして「自己教師あり学習」について解説した。次回の記事では、ChatGPTに使われている人との対話に特化するための技術「人間からのフィードバックに基づく強化学習」について解説する。
(top image credit: unsplash Shubham Dhage)



更新の通知を受け取りましょう
 気になるトピックスが、きっと見つかる
気になるトピックスが、きっと見つかる  他では得られない独自の知見
他では得られない独自の知見  交流から生まれる新たな価値
交流から生まれる新たな価値 












投稿したコメント