

【必見】AIらしさを無くす画像生成AIのコツ

こちらのトピックス“生成AI最前線「IKIGAI lab.」”は、学び合うことを目的としたオンラインビジネスコミュニティ「OUTPUT CAMP meets AI」のメンバーで運営しています。
私、伊藤は普段、生成AIの導入・活用支援を行い、親子向けの生成AI体験イベントを開催しています。生成AIの情報を常にキャッチアップし、新しいツールに興味があれば実際に使ってみるのが私のスタイルです。
今回は緊急企画第二弾です!
Midjourney V6はMidjourney V5.2と比較して、「現実的な美しさの生成が得意になった」印象があります。その進化と使い方に焦点を当てて解説します。
ちなみに前回記述した生成AI EXPO in 犬山のレポートなどは緊急企画が終わったら掲載します(先にMidjourneyの事を書きたい)。
前回の書いた記事はこちらから。
V6でイメージ通りの画像を創ってみよう
初めに、私は写真画像を生成することを「写真生成」と呼んでいますので、この場ではそのように言わせていただけたらと思います。
プロンプトについてですが、基本的には変わらないのですが、独自の世界観を再現しようとすると、より詳細の情報が必要になったと感じています。

今回はこの画像をどう出していったのか順を追っていきます。実際には何度も出してここにたどり着きました。
まずは「白いバラの姫様」「明るい写真」をイメージしました。そのままそれをプロンプトにしてみましょう。


予想通りバラだけが出たりしました。
なぜ、予想通りだったのかというと、衣類の指定などをしていなかったからです。プロンプトには逆光であること、ハイキーで明るい写真であることなどを入れましたが、あまり汲み取られていません。
試しに「露出補正+2」と英語でプロンプトに入れてみましたが、全く反応しませんでした。なので「露出補正+2」はプロンプトから削除します。
次は、バラのドレスを着ていることをプロンプトに入れます。

まだ足りないですし、もっとバラ感が欲しいです。
また、写真の再現をするとはいえ、広告写真や報道写真ではなくアートフォトとして生成したかったので「art photo」を最初に入れます。

その他、頭にバラでできた被り物をしているとプロンプトに追記しました。すると、それに引き寄せられてかドレスもバラの感じが強くなってきました。
「art photo」と明記することで、Midjourneyに「アーティスティックな写真でよろしくね」とこちらの意志を明確にします。
ただ、半身くらい写っている状態で生成したかったので縦構図に切り替えました。Midjourneyは横構図で全身が写る写真生成はかなり困難です。
「fullbody shot」と入れてもなかなか出ません。衣類の指定をしっかりする必要があります。また、良くない生成結果のリスクが高くなります。

良い感じになってきましたが、私は、「全て白で構成された写真にしたい」ということに気づきました。
プロンプトにその要素を入れます。

そしてここに辿り着きます。
ここでの特徴は、
・肌を白色にするために「アルビノの女性」を入れました。
・白色の背景にするために「white back ground」を入れました。
・はじめの方に「White love」を入れています。
「White love」の重要さ
ある程度、統一した色で再現する際に「●● color style」と入れたりすることがあります。
例えば、薄紫色で統一する場合は「pastel purple style」などと入れます。
更に統一した色で出したいときに「●● love」が有効になります。
最後はphotoshopで仕上げ
露出補正やホワイトバランスの調整などは、photoshopを使ったの方が速いです。フィルタの「Camera Rawフィルター」を使えば一眼レフなどで撮れるRAWデータ写真の編集とほぼ同じ編集ができます。ぜひ試してみてください。

ここまで明るくする事ができました。
そして、普段から実際にカメラで写真を撮っているからこそ、とある点に気付きます。
Midjourneyは構図が素晴らしい
Midjourney V6になってから、色や出力されるアート性の傾向が変わったことは前回の記事で認識できたかと思います。
Midjourneyってキレイな写真画像が出ますよね。
実は、Midjourney V6では、前回と比べて構図の理解が進んでいるのです。

こちらの画像はMidjourneyV6で生成したものです。
・赤い縦と横の線…三分割構図
・赤い対角線…対角線構図
・青と白の線…黄金比
写真を撮るときは最低でも三分割構図を抑えておくべきです。
それを意識することで、良い写真が撮れるようになります。
上記の画像のように、被写体が下記3つのポイントを押さえて配置されているのは、とても良い構図の例です。
・右目に赤い線が通るような配置
・左下から右上の対角線が肩と顎と髪の側をキレイに通るような配置
・黄金比で見ると、大きな白の丸の中に被写体がキレイにおさまる配置
こんな感じで良い構図で生成ができてしまうのです。

こちらはMidjourney V5.2で生成したものです。V5.2も構図の良い画像が出る時があるのですが、歩留まり率が非常に低いです。
このような良い構図で出るのは、20回に1回くらいの感覚です。
生成された瞬間から、「この写真は美しいな」と感じていましたが、分解して考えると最高の構図でした。
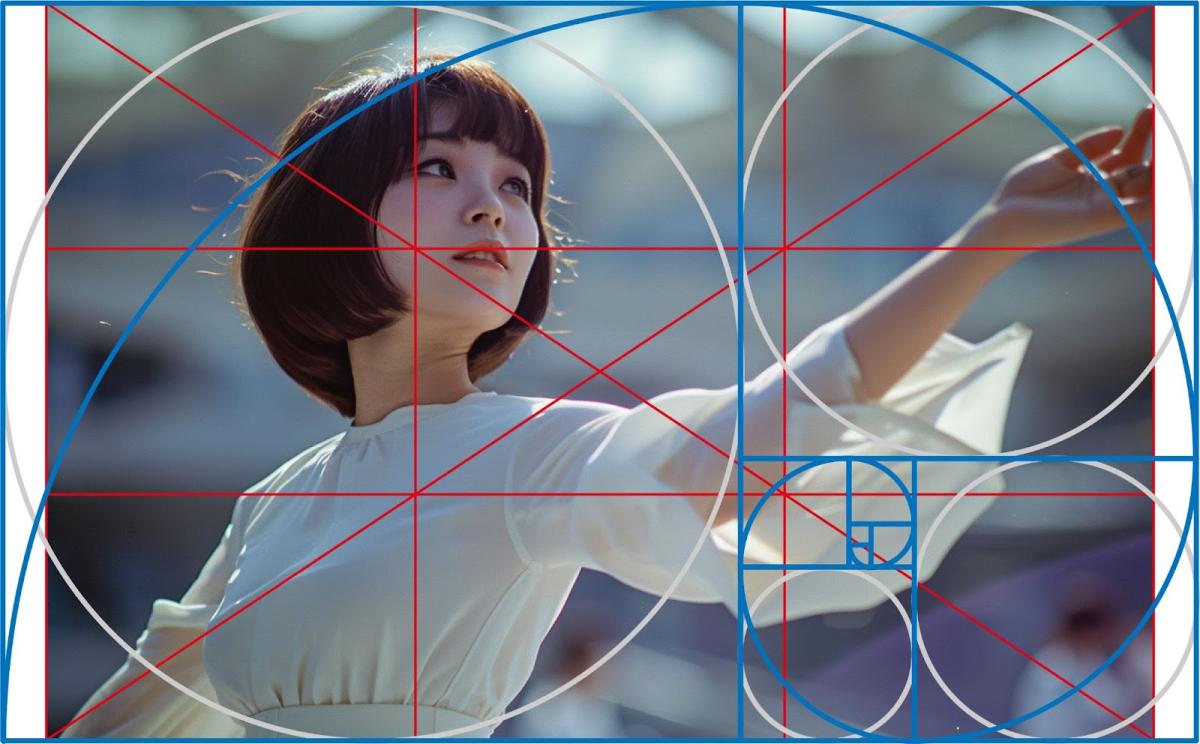
さて、またV6に戻るのですが、こちらの画像は完璧な構図で震えました。
一番大きな円に被写体と体が収まり、目線の先にはしっかり余白があります。
自然と目線を斜め上に向けるような導線になっており、伸ばした手の先は2番目に大きい円にぴったり収まるようになっています。
生成された瞬間から、「この写真は美しいな」と感じていましたが、分解して考えると最高の構図でした。

こちらの画像は前回の記事のトップ画像で使われたものです。
こちらの場合は、一番大きな円に女性と飛ぶ鳥が入って、2番目に大きい円の中にキレイに鳥が羽ばたいている様子が収まっています。
また、左下から右上の対角線上には鳥の目、鼻、女性の目の前にいる鳥の羽の先端を通っていて美しいです。
また、やりすぎかもしれませんが、反転したら美しすぎた例を紹介します。

水平で反転させたものです。
一番見せたい女性部分と鳥のほとんどが、しっかり大きな円に収まっています。2番目に大きな円は鳥がキレイに収まっています。
3番目に大きな円にも鳥が収まっています。ここまでキレイにハマる事に震えました。

こちらも反転した画像です。

こちらはとある自治体をイメージして生成したV5.2のプロンプトをV6で生成した結果です。





色々説明してきたので、もう分かってきた方も多いのではないかと思います。
これもまた、とても美しい構図です。
V6はこのような構図の美しい写真生成がかなりしやすくなっています。
弱点としては、横構図で全身やほぼ全身が写っている人の画像、イラストであったり、再現したい要素が多かったりするいと、画質が安定しなくなることがあります。
この画像をベースに解説していきます。

よく見ると顔が崩れています。
この様な生成結果における顔の部分は、空間周波数が高くなっています。
光の情報量も多くなり、この様な画像全体の占める割合の小さな部分では顔の生成は困難になると推察しています。
1 秒間あたりに変化する波の数を「周波数」と表します。画像では、位置によって(空間的に)明るさ(信号)が変化しています。このような空間的に変化する信号の周波数を「空間周波数」といいます。
ヴィスコテクノロジーズ株式会社より
つまるところ、空間周波数とは、僅かな場所で急激に明るさが変わる部分が空間周波数が高い所になります。
実際に空間周波数を分析してみました。
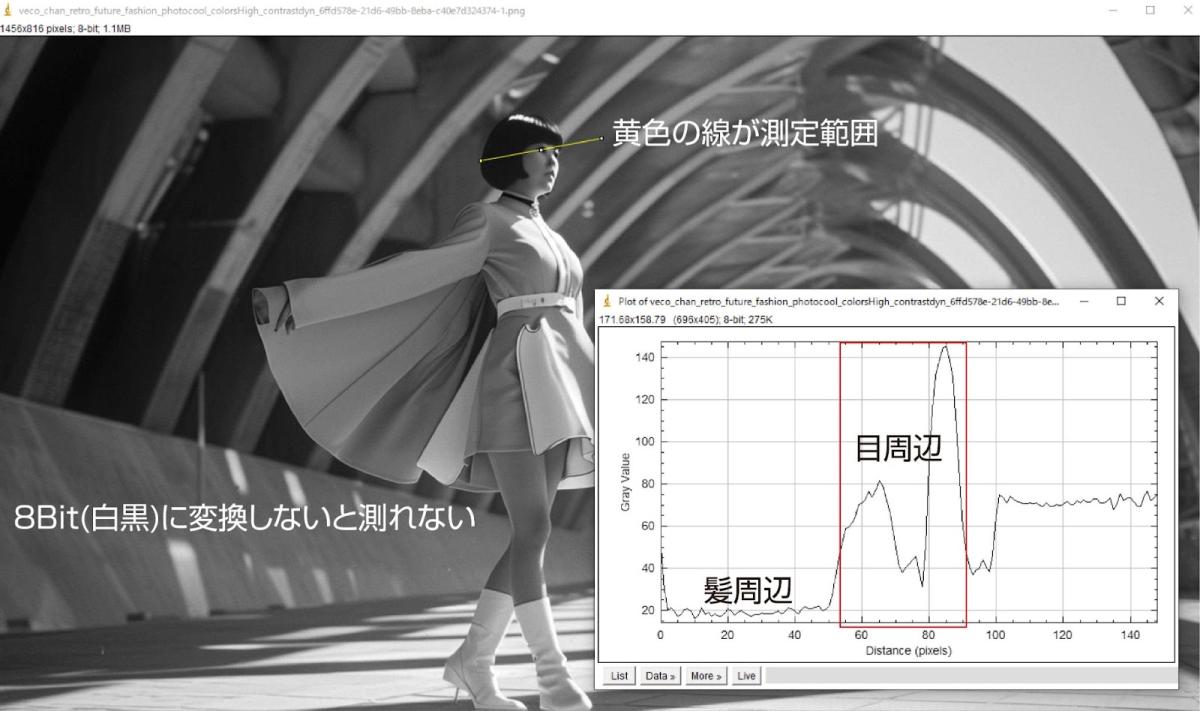
顔が崩れた例を基に、顔の付近で空間周波数を測定しました。
すると、目の周りはふり幅が大きくなっています。
それでは、別の画像で見てみます。
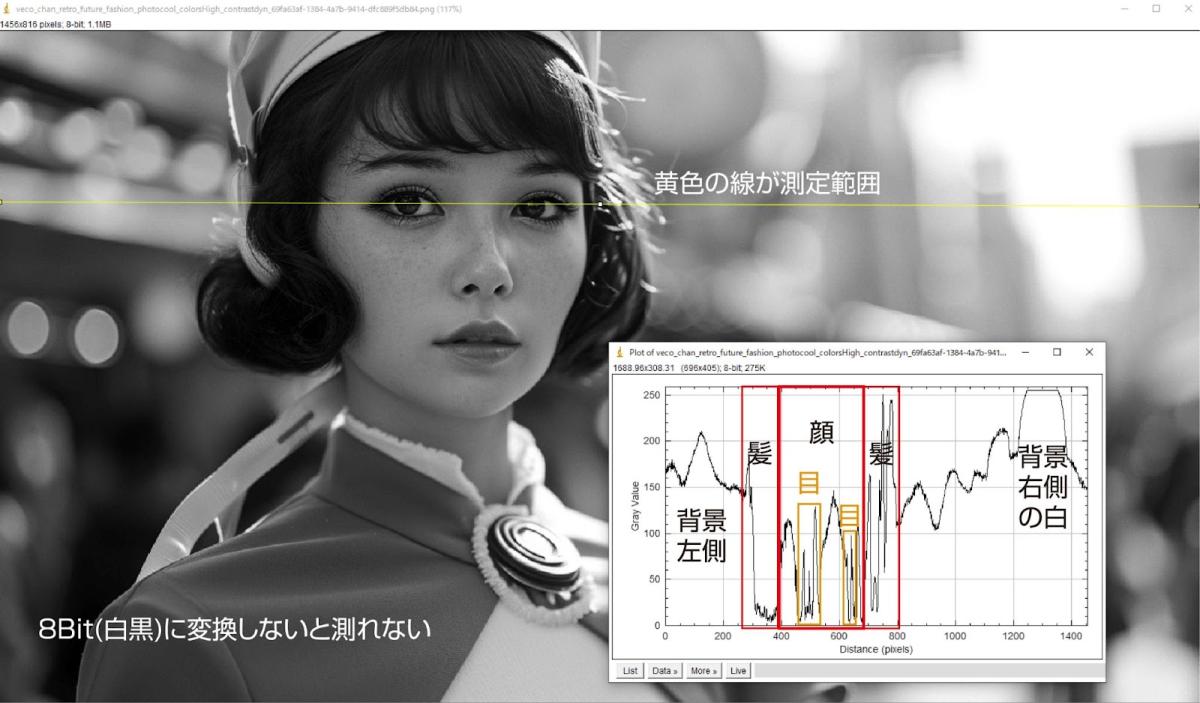

実際にどのくらいのピクセルになっているのかを測りました。
人間の複雑な顔を60pixel程度で生成しようとするので、それは無理な話だったのだろうと推察します。
しかし、どちらかと言うとV6はこれが特に苦手なように感じます。そこに関しては、感覚的にV5.2の方が得意です。
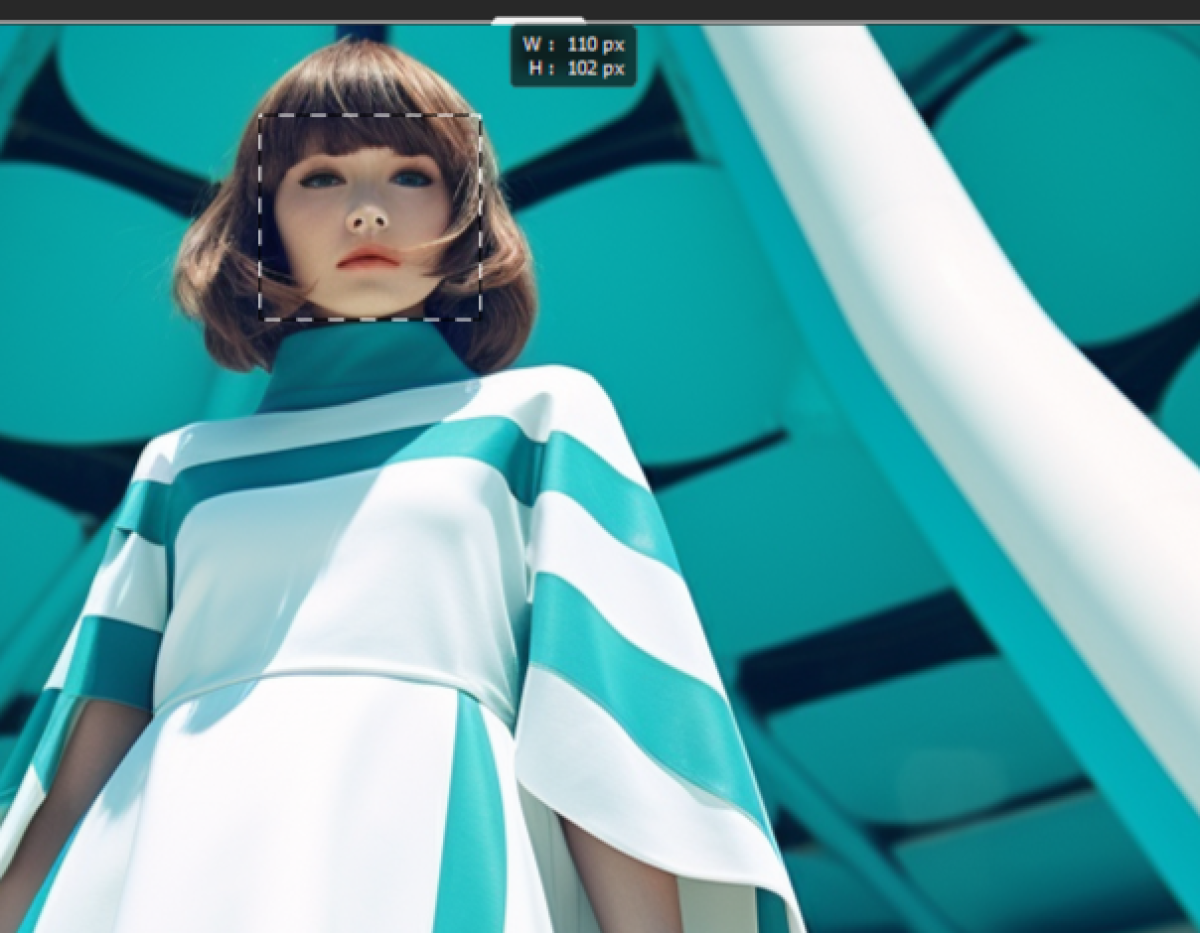
近い顔のサイズを用意しましたが、比較的V5.2の方が安定して生成されていることがわかります。これは同じおなじプロンプトで生成しています。
元の画像はこちらです。

ここで、スタイライズをかけるとどうでしょうか。
スタイライズとは、--sというパラメーターになります。
0~1000までの数値で機能します。何も指定しなければデフォルト値は100に設定されています。

スタイライズを300に設定しました。
急激に画像が安定しますが、これはスタイライズにより画質を上げる方を優先して、ある程度のプロンプトを無視しつつ生成した結果です。
スタイライズをかけても全身の画像は顔が崩れていました。
横の全身を出力するのは本当に難しいです。
画像全体の割合で、顔が小さければ小さいほど描写する顔としてのオブジェクトが多くなるので崩れやすくなります。
体も状況によっては崩れます。
全身はできるだけ縦画像で出した方が良いです。
どうしても横画像で安定して出したいときは、V5.2をおススメします。
オブジェクトが多いと、横画像かつ全身でない場合でも、崩れること事があります。
midjouneryのスタイライズとポジティブワード

先ほども挙あげたように、特に全身が写っている写真画像の生成では体の一部分、或いは顔が崩れやすくなります。
ただ、Midjourney側は「『8k ultra』などといった、抽象的に解像度が上がると認識するようなプロンプトを入れないでください」と呼びかけています。
ただ、例外があると私は感じていて「フォトコンで優勝した」などのプロンプトは有効だと考えています。
これをここでは「ポジティブワード」と言わせてください。
特に、V6の場合の「フォトコンで優勝した」は、構図だけでは無く、光の当たり方なども含めた描写の変化が見られます。
また、スタイライズをかけると全体にシャープさが加わるようになります。
なぜそうなるかというと、フォトコンで受賞する要因は様々ありますが、計算し尽くされた構図や光の当たり方などもあります。
Midjourneyにおける「フォトコンで優勝した」は、まさにその流れを汲み取っている様に感じます。

顔が崩れているのであまりよろしくはないですが、冬を勝手に認識した例です。
生成する時期によって衣服と背景も変化します。
衣服は色やファッションの傾向を指定していますが、生地までは指定していないので勝手に判断してくれました。
Midjouneryの文化の判断基準はアメリカ基準?
世界に注目される日本文化の1つに、和食があります。
日本には寿司やラーメン、うどん、そば、牛丼など色々あります。
Midjourneyで日本の食べ物を出してみるとどうなるか見てみましょう。

やきそばの場合はキレイに写真がでてきました。
これにはびっくりしました。深夜に出したので空腹感が増したこと事を覚えています。
ここからイラストで生成したものが右になりますが、sobaの文脈を捉えて別の食べ物になりました。
もしかしたら特定の地域ではどんぶりで食べる文化がはあるのかもしれませんが、私は知らないので違和感を覚えました。

マグロを英語にするためにtuna sushiを試してみました。
そうすると写真の方については、鉄火巻きはできましたが、カリフォルニアロールみたいなものがたくさんできました。
イラストにすると、まぐろの寿司が出力されにしっかりなりました。
ちなみに、japanese tuna sushiと入れるとしっかり再現できます。

Midjourneyのオブジェクトの理解はアメリカ基準?
ズバリですが、日米間の文化判断基準差が生成結果にギャップをもたらしていると考えています。
例えば、まぐろの寿司ではなぜイラストで出て、やきそばは写真で出るのかを考えてみました。
これはあくまで推察ですが、「アメリカの寿司はカリフォルニアロール的なものが多いのかな」と感じています。
そうなると、「アメリカにいる日本人が感じるまぐろの寿司は、イラストでよく見るもの」となっている可能性があります。
やきそばは写真では見るけど、イラストではあまり見ない(日本でもあまり見ない)。
なので、写真ではうまくいくけどイラストではうまくいかないのかもしれません。
見えないところで魅せる画像生成
ありがたいことに、最近X(旧Twitter)でバズりました。
ご覧いただいた皆さまありがとうございました。
バズった投稿がこちらです。
とあるビジコンの資料のために写真生成をした画像をしれっと入れたら、生成画像だと全く気づかれなかったでござる。 pic.twitter.com/8WYAfhSRW4
— studio veco@AI×地域貢献 (@studio_veco) January 14, 2024
テキストの通りの状況がありました。
プレゼンの最後に最期に「実はスライドの画像は全部画像生成で創ったんですよ」とポロっと言ったら、みなさん驚いてました。

目的がはっきりしていれば、そこに向かって最適な画像が生成できるのはMidjourneyの良いところです。
有料会員なら商用利用も可能なので、社会人の市場価値を上げるきっかけとしてもMidjourneyを使うのはおススメですよ!
さいごに
Midjourneyは本当に楽しいです。
Midjourneyによって、私は自分の表現したいものを脳内の世界から、綴る言葉によって現実世界に具現化することができました。
自分の表現したいものが表現できるようになり、そこから更に新しいインスピレーションを得て、クリエイティブ目線においてもより高みを目指すことができるようになりました。
写真を撮っている私にとっては画像生成は脅威ではなく、カメラの延長線上にあるイメージで使っていて、むしろ歓迎しています。



更新の通知を受け取りましょう
 気になるトピックスが、きっと見つかる
気になるトピックスが、きっと見つかる  他では得られない独自の知見
他では得られない独自の知見  交流から生まれる新たな価値
交流から生まれる新たな価値 












投稿したコメント