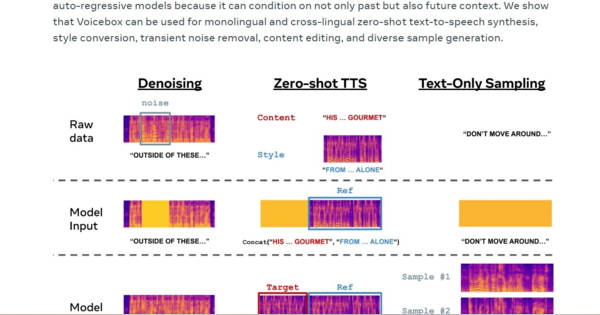
Meta、音声生成AIモデル「Voicebox」発表 ノイズ除去や言い間違い修正、多言語会話など多機能
コメント
注目のコメント
音声通訳がまた一歩進んでますね。声質学習は日本語でもオルツ等いくつかあります。問題は何分で学習できるか。
この次は抑揚やイントネーション、さらには口癖等の口調を学習です。これは方言対応でもあります。ここまで来れば、しばらく会話しても本人か気付かないでしょう。
翻訳コンニャクは日本人の夢。期待したいです。
もっともオレオレ詐欺やデジタル移民による雇用喪失等、負の側面にもそろそろ注意が必要ですが。STT (スピーチの書き起こし) についてはOpenAIが昨年Wisperという高精度のモデルをオープンソース化しており、ChatGPTの学習データを作る上でも活用されたと見られますが、TTSについてはまだ決定的なモデルは出てきていない状況です。日本語対応のモデルとなるとさらに選択肢はさらに狭まります。私の知る限りではLineの研究グループの取り組みが特に進んでいるという印象です。
TTSにおいてはただのテキストとは異なり、発音やイントネーションなど、文字だけでは表現できない要素が多いことも研究の難易度を上げているところです。LLMモデルのネクストレベルとしてそういった発話のニュアンスも含めた音声データをそのまま学習するようなアプローチが実現する日がいずれは来ると期待されますが、まだそのような手法は確立されていません。
