
2023/4/30
【教えてプロ】日本のAI「周回遅れ」を挽回するには?
NewsPicks コミュニティチーム
この3〜4月は、ChatGPTをはじめ生成AIの関連ニュースが一気に増えた。そう感じている人は少なくないのではないでしょうか。
先週の【#教えてプロピッカー】で取り上げたChatGPT関連の要人来日の話題にも、多くのPICKがつきました。
その「後編」にあたる本稿では、この盛り上がりが日本のAIビジネスをどう加速していくのかを考察していきます。
(※コメント欄でピッカーから質問を募る「#教えて」シリーズの詳細はこちら)
INDEX
- 🇯🇵 日本のAI産業は巻き返せる?
- 💡 組み合わせのアイデアで勝つ
- 🔢「機械学習天国」ゆえ可能な研究を
- 🚚「製造業×AI」で世界に打って出る
- 次回「#教えて」シリーズは5/7予定
🇯🇵 日本のAI産業は巻き返せる?
4月23日掲載の前編(下の記事)では、OpenAIトップのサム・アルトマンやMicrosoft副会長の来日が生成AI市場にどんな影響を与えるのか?という質問を受けて、プロピッカーの和田 崇さんに解説してもらいました。
続く後編では、もう少し中長期目線で考えた「日本のAI市場の展望」を紹介していきます。
続く後編では、もう少し中長期目線で考えた「日本のAI市場の展望」を紹介していきます。




前編では、ChatGPTが“日本びいき”になっている理由を
- 技術面で入り込みやすかったから
- 著作権法が「機械学習天国」だから
- 今年のG7議長国だから
- 文化的に相性が良いから
という4つの側面から考察しました。
会話型AIサービスのChatGPTを使う日本人ユーザー(時事)
私のつたない考察にご賛同いただけたかはさておき、やや周回遅れだった日本のAIビジネスに、追い風が吹いていることは間違いありません。
そこで後編では、この状況を未来にどう生かしていけるのかを、AIビジネスにかかわる者の1人として考えていきます。
私が所属するLaboro.AIは、AIを使ってさまざまなソリューションをオーダーメイド開発する「カスタムAI」を提供しているベンチャーです。日々の活動を通じて得た情報や、お客さまのご要望などから考えると、今後は
【1】特化型生成AIの普及
【2】大規模言語モデルの応用
【3】独自基盤モデルの開発
のそれぞれで、日本独自の展望が考えられます。以降で詳しく説明していきます。

(iStock / hamzaturkkol)
なお、AI開発界隈では、お客さまに「こういうAIを作りたい」と言われてすぐに「できます」と答えるベンダーは信用できないと言われます。
あらゆるAIのモデルは、【Aというタスク】ができても【類似のA’もできる】とは限らないからです。
それゆえ以降の考察も、「必ずできる」という話ではありません。AI技術に詳しいピッカーの方々は、ぜひご自身の見解をコメント欄で教えていただけたら幸いです。
💡 組み合わせのアイデアで勝つ
【1】特化型生成AIの普及
ChatGPTのみならず、画像生成AIの
- Stable Diffusion(ステーブル・ディフュージョン)
- Midjourney(ミッドジャーニー)
- DALL・E2(ダリ ツー)
などメジャーな生成AIモデルを活用して、日本ならではのデータを学習させながらサービス開発に取り組むディベロッパーが日に日に増えています。
いくつか具体例を挙げましょう。
すでに旅行情報の提案比較サイトの「AVA Travel(アバトラベル)」や、旅行プラン作成アプリの「ミッケ」などは、
旅行データ × ChatGPT = レコメンド
でLINEを使った会話型サービスを展開しています。
ほかにも、パーソナルスタイリングサービスの「DROBE(ドローブ)」は、
ファッションデータ × ChatGPT = レコメンド
でユーザーにコーディネートアイテムを提案する「AIスタイリストさん」のβ版を発表しました。

「AIスタイリストさん」のUIイメージ(DROBEのプレスリリースより)
今後はこういったジャンル特化型の生成AIが、BtoC分野だけでなく、企業の業務効率化を促すようなBtoB分野でもたくさん生まれるでしょう。
ただしここまでは、ピッカーの方々も想像の範囲内なのではないかと思います。
人間がやっていたことをAIが置き換えていく、という文脈上にあるからです。
日本から、世界の先例となるようなAIサービスを生み出すには、もう1〜2歩踏み込んだ開発が求められます。
その点で期待しているのが、続いて説明する「大規模言語モデル」と「独自基盤モデル」の開発です。
🔢「機械学習天国」ゆえ可能な研究を
【2】大規模言語モデルの応用
ChatGPTを運営するOpenAIが日本展開を強化する今の状況は、彼らが開発する大規模言語モデル(以下、LLM:Large Language Models)について学ぶチャンスです。
これを生かさない手はないでしょう。個人的に注目しているのは、LLMを市場調査やマーケティング調査に応用する動きです。

(iStock / metamorworks)
LLMは、インターネット上にある人の知恵で構成された大規模ネットワークと捉えることができます。
違う見方をすれば、言語による「人間社会のパラレルワールド」を形成しているとも言えるでしょう。いわば言語版のメタバースです。
であれば、現実社会でも起こるであろう事柄の予測シミュレーションを行うために、LLMを使うという可能性もあるのではないかと。

(iStock / XH4D)
実際に、スタンフォード大学とGoogleリサーチの研究チームが、この4月に興味深い実験結果を発表しています。
GPT-3.5を搭載した複数のAIエージェントを作り、仮想の町に解き放ったところ、彼ら・彼女らは「リアリティのある社会的行動をする」と結論づけられたそうです。
▶︎25人のAIが一緒に暮らしたら、自我は芽生えるか? ゲームの中で検証 バレンタインなど勝手に企画(ITmedia NEWS | 2023年4月13日)
AI同士が次期町長候補について議論したり、パーティの主催を指示されたAIエージェントが集客や会場の飾り付けを行ったり......。
人間と同じく、「自ら考えて」社会的な行動を取ったのです。
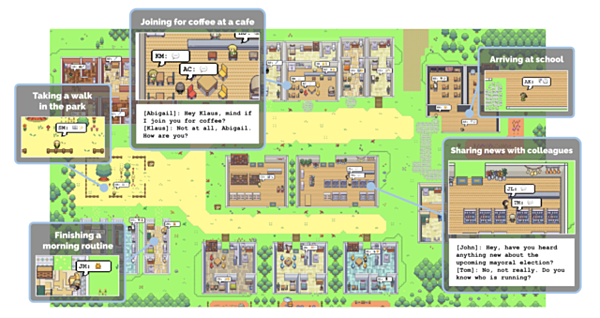
実際の実験画面(Generative Agents: Interactive Simulacra of Human BehaviorのPDFより)
LLMを使ってこうしたシミュレーションができるならば、これまで調査会社や国家機関が長期間かけてやっていた社会・経済調査の簡易版を、短時間かつ低コストで行えるようになります。
前編で、日本の著作権法はAIの学習用データを利用しやすいと説明しました。だからこそ、日本版パラレルワールドを作り出すこともできるのではと想像されます。
日本独自の文化を擬似的に反映した環境で、仮説検証ができる──。
これはAI活用を進める上で、他国に比べて大きな強みになるはずです。
🚚「製造業×AI」で世界に打って出る
【3】独自基盤モデルの開発
ここで言う「基盤モデル」とは、本来は1つのことしかできないAIを進化させ、さまざまな仕事をこなせるようにした「マルチタスクなAIモデル」のことです。
ChatGPTのベースとなるAIモデルの「GPT」も、大量に学習したデータを基に、生成も要約も翻訳もリコメンドもできる言語版の基盤モデルとして位置付けられます。

(REX / アフロ)
基盤モデルを支える「大規模データ」は、言語だけとは限りません。
すでに、画像データを大量に集めて学習し、実際の写真と見間違えるクオリティでビジュアルを生成するAIサービスもあるわけです。
であれば、今後センサーデータを大量に学習した基盤モデルが登場するような流れも生まれるのではないかと考えています。
例えば工場の製造ラインにおける作業員の行動データや、製造・生産工程のデータをセンサーを介して取得し、モデル化するとしましょう。

(iStock / metamorworks)
それを国全体で集めてAIに学習させれば、日本の強みであった製造業の優れた知見を、企業の壁を超えて共有できる基盤モデルとなるかもしれません。
「こういう仕様の製品を作りたい」と入力すれば、理想の設計書や生産計画がすぐに出力される。
「生産ラインのコストを削減したい」と入力すれば、日本中の工場データから導き出した最適な生産ラインの組み方を提示してくれる。
そんな基盤モデルを日本で独自開発できれば、デジタルな「新・製造大国」として復権する道が見えてくるのではないかと思っています。

(iStock / metamorworks)
この妄想レベルの話を実現させるには、どうやって大量に製造現場のデータを集めるのか?という課題を解決しなければなりません。
センシングに必要な設備投資費はどうするのか。製造各社がAIの学習用にデータを提供するインセンティブはどう設計するのか。問題は山積みです。
それでも、言語を駆使するAIモデルの研究開発で米中の後塵を拝してしまった日本が、AIの世界でグローバルに価値を発揮するべく、こうした基盤モデルの開発に賭けるという発想は悪くないと思うのです。
そのけん引役になるのは、トヨタグループのような大手メーカーなのか。国が主導して大規模データの連携基盤づくりを進めるのか。
はたまたキャディのような製造業向けソリューションを提供するスタートアップが突破口を開くのか。

最後は荒唐無稽なアイデアになってしまいましたが、せっかくAI活用が盛り上がってきた今だからこそ、我々も日本から「大きなAI構想」を生む一翼を担えればと考えています。
次回「#教えて」シリーズは5/7予定
NewsPicksは、これからもピッカーの「もっと知りたい」にお応えしてまいります。
【#教えて編集部】【#教えてプロピッカー】でいただいたコメントには、全て目を通しておりますので、たくさんの「問い」をお寄せいただけたら幸いです。
また、問いに対する答えは1つではなく多様であるため、追加取材した記事の内容も1つの意見だということをご認識いただけましたら幸いです。
文:和田 崇、伊藤健吾
編集:佐藤留美
デザイン:九喜洋介
作成協力:NewsPicksコミュニティチーム
編集:佐藤留美
デザイン:九喜洋介
作成協力:NewsPicksコミュニティチーム
