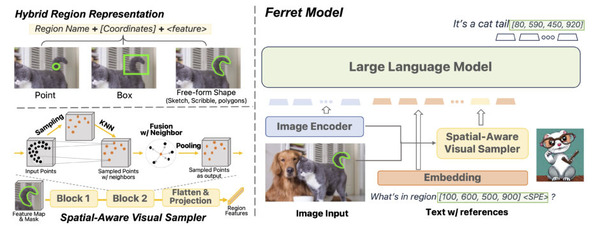

アップルがマルチモーダル大規模言語モデル「Ferret」を公開。画像内の形や場所を言葉で説明
コメント
注目のコメント
大規模画像言語モデルは他にもありますが、Appleが発表したのはニュースですね。
正確な画像内位置参照は、いかにもVision Proに搭載されそうな技術です。GAFAM 全て(出資含む)がLLMを公開し、2023年はAI戦国時代の幕開けとなりそうですね。
このままGAFAM 中心に進むのか、それとも新興企業が大きくなるのか、企業動勢も気になるところ。ついにAppleから大規模言語モデルについての情報が来ましたね。
これまでAppleはAIないしLLMといった言葉を伏せてきた印象でしたが、やはり内部では開発が進んでいたということでしょうか。(ChatGPT/GPT-4の技術を活用し...と書かれていますね)
Ferret、MLLM(マルチモーダル大規模言語モデル)ですが、ボックスシルエットではなく、形状をフィットさせて認識することが出来るようです。
BartにGPT-4やLLaVAなど、MLLMが多く登場したここ数か月でしたが、今後も更なる発展が期待できそうです。
