
2021/9/21
東大生を超える「日本語AI」、最新の頭脳をあなどっていないか

株式会社ELYZA | NewsPicks Brand Design
NewsPicks Brand Design Senior Editor
「どんな文章でも、AIが一瞬で3行に要約する」
今年8月、あるサービスがSNSを大きく賑わせた。
ニュース記事や小説のような整った文章だけでなく、リアルタイムで取られた議事録や会話録のような乱雑なテキストにまでも対応する高精度な長文要約AI。
900文字程度のテキストであれば、人間が5分程度かかる要約を、AIは10秒で実現するという。
公開から5日で13万人が利用した、話題のサービスを開発したのは「ELYZA(イライザ)」。
AI研究で名高い東京大学松尾研究室発であり、「自然言語処理(NLP)」の研究開発・社会実装・サービス開発を手掛けるスタートアップだ。
NLP(Natural Language Processing)とは、人間が普段使っている英語や日本語などの「自然言語」をプログラムで分析・処理する技術。身近なところでは、検索エンジンや機械翻訳などに用いられている。
現在は大きく注目を集める同分野だが、実は少し前までは形勢が違った。
ELYZA創業者の曽根岡侑也代表は、「NLPでの起業には反対もありました」と明かす。
「絶対に成功しないし、万が一、うまくいったとしても『日本語』という言語に縛られてグローバル展開ができない」。そんな厳しい忠告も受けた。
しかし曽根岡氏は、2018年にELYZA創業に踏み切り、2020年9月には日本語に特化したAIエンジン「ELYZA Brain」を開発。
その後、わずか5か月ほどの間に50~60社の企業から引き合いを受けた。その多くはNLPの導入を試み、挫折を経験した企業だという。
NLPにこれほどの注目が集まっているにもかかわらず、社会実装が難しいのはなぜか。そして、ELYZAが同分野で独走する理由とは。曽根岡氏に話を聞いた。
なぜ、反対の声に屈しなかったのか
曽根岡 絶対に成功しない──。そんな声を受けても、私たちがNLPで起業した理由はシンプルです。
我々の日々の仕事は、話したり文章を書いたりと、そのほとんどが言語を使う業務です。
一般に知的生産に携わるとされるホワイトカラーの方でも、ひたすら契約書を読んだり、文章の中から重要な部分を抜き出したりと、テキストに関する非効率な単純作業をたくさんしている。
ここをAIでサポートできれば、日本の社会全体に大きなインパクトを生み出せます。
せっかく5年、10年となんらかの事業にチャレンジするのであれば、まだ解決されていない領域で、自分たちが最もワクワクすることに賭けるべきだと思ったんです。

「BERT」がもたらしたパラダイムシフト
いまでこそ脚光を浴びるNLPだが、つい最近まで画像認識や音声認識に後れをとっていた。
曽根岡氏が所属する松尾研でも、NLPを研究しようとする者は少数派だったという。
その状況は、いつ、どのようにして変わり始めたのだろうか。
曽根岡氏が所属する松尾研でも、NLPを研究しようとする者は少数派だったという。
その状況は、いつ、どのようにして変わり始めたのだろうか。
画像認識や音声認識の分野では、ディープラーニングの登場により、2015年頃から人間を超えるAIが現れはじめました。
これらの技術は車の自動運転や税関や空港での顔認証、Siriのようなバーチャルアシスタントなど、すでにさまざまな場面で使われています。
しかし、NLPのように言語を扱うAIは、画像や音声に対し、3、4年ほど後れをとっていました。
言語理解タスクの精度を示す「GLUE」のスコアは、2017年末時点で人間が87.1、AIが65.6。出題される問題は大半が二択で、すべてに「Yes」と答えても50点は取れる内容ですから、相当、低い数値です。
これでは人間の作業をAIで置き換えることなど、とてもできません。
結果としてNLPが使われるのは、コールセンターのチャットボットや、SNSにおける評判分析など、精度が低くても問題ない場面に限られてきました。
なぜ、NLPの分野では進歩が遅れていたのか。
その理由は、データ化の難しさにあります。画像や音声は、センサーで数値データに直接変換できる信号情報であり、コンピューターで扱いやすいという特徴があります。
一方、言語は、人間が勝手に名付けた記号情報。文脈や常識を加味した上で、その意味を汲み取り、数値データに変換することが困難なのです。ここが大きく足を引っ張っていました。
しかし2018年10月、NLPの世界で大きなパラダイムシフトが起こります。
Googleが「BERT」という大規模な言語モデルを発表。これによって言語理解タスクの精度が大きく向上し、英語データを使った実験では2019年6月、AIが人間を超えました。

何が「日本語AI」の開発を阻むのか
BERTの登場で、NLPの世界ではパラダイムシフトが起きた。
にもかかわらず、日本ではまだ実用の域に達しているとは言いがたい。それは、なぜなのか。
にもかかわらず、日本ではまだ実用の域に達しているとは言いがたい。それは、なぜなのか。
英語圏や中国語圏では、BERT以降の大規模言語モデルを早い段階で社会実装する動きが起きました。
たとえば、Googleは2019年に大規模言語モデルを検索エンジンに導入。その他、多くの企業でもすでに活用されています。
しかし、すべての言語でそうだというわけではありません。
ここには「日本語の壁」が存在します。英語は多くの国で用いられている言語ですから、モデルの研究もおのずと進みます。
一方、日本語の場合は残念ながら、そうではなかった。メジャースポーツとマイナースポーツにおける競技人口の差みたいなものです。
大規模な日本語モデルは、日本では開発されていませんでした。
それはなぜか。一つは、学習データ量の問題と計算機コストです。
大規模言語モデルでは、十分なデータ量を学習させないとインパクトが生まれません。しかし、モデルサイズやデータ量を増やすと処理に使う計算機のコストが莫大にかかってきます。
1回の試行錯誤で、500万〜1000万円以上かかることも珍しくない。
加えて、当時は大規模言語モデルの開発に関して事例も、うまく学習するためのノウハウも少なく、それだけの大金をかけても実際に精度が出るかどうかの確証は持てませんでした。
そうなると、体力のないスタートアップは挑戦できないし、大企業では稟議が通りません。
以上のような事情もあり、すでに一般公開されているライブラリやモデルを用いてAI関連サービスを作る企業はありますが、研究開発をして、一から大規模なモデルを開発するスタートアップは多くないのです。

もちろん、そういった企業を否定するつもりはありません。
もし我々が同じ方針を採ったとしても、市場はAIブームですから、おそらく株式上場できるくらいの成長可能性はあるでしょう。
ですが、日本語をベースにしたモデル自体が進化しないと、真に驚きのある、社会に大きなインパクトを起こすサービスは生まれません。
我々のミッションは「未踏の領域で、あたりまえを創る」です。
新しい価値を生み出すためには研究開発から社会実装、サービス開発までをシームレスにつなげるべきだと考え、全方位で取り組んでいます。
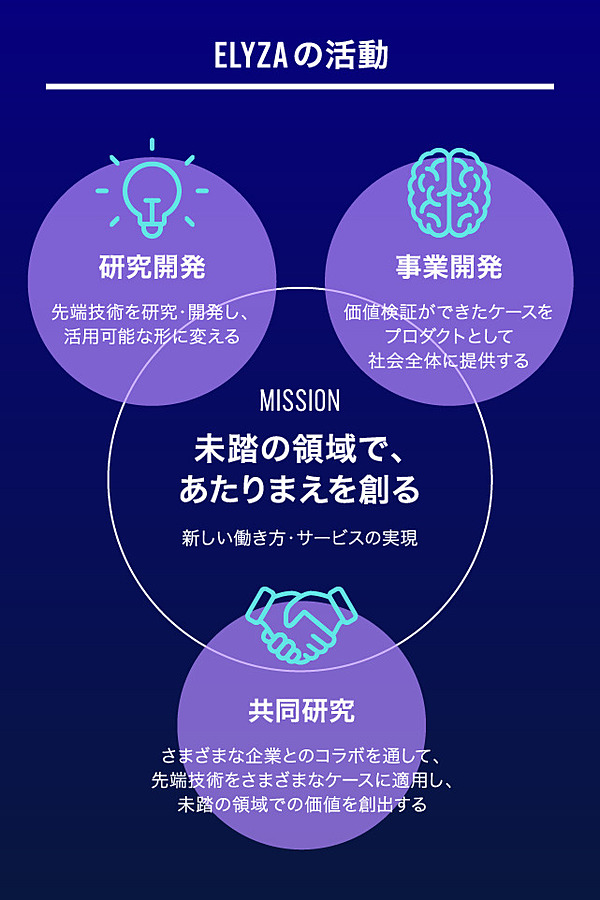
その想いのもと、開発した日本語特化AIエンジンが「ELYZA Brain」です。
もちろん、研究開発には時間もコストもかかります。
しかし、NLPで新しいインパクトを起こす、と起業したからには、大きな変化が起きるとわかっているタイミングで投資しない選択肢はなかった。
たとえ、失敗したとしてもよかったんです。「大規模言語モデルの開発には、こんな難しさがあるんだ」と学べますから。
やはり開発で苦労したのは、学習データの収集です。Web上にある英語ドキュメントの量を10としたら、日本語のドキュメントは1程度。
ここは開発の肝となるため詳しくお話しできないのですが、モデルの精度を高めるため、課題に正面から取り組んできました。

こうして生まれたELYZA Brainに、日本語テキストの分類問題を解かせ、東大生の結果と比較したところ、ELYZA Brainの精度が83%だったのに対し、東大生は80.6%。
ついに、日本語特化のAIエンジンが人間超えの精度を出す日が訪れました。

ELYZA Brainは社会実装の段階へ
では、ELYZA Brainを実際のビジネスに適用したら、どんな効果が生まれるのか。
活用の可能性を探るため、同社は2020年9月、「NLP30」と銘打ち、技術を社会実装するためのパートナーを募った。
活用の可能性を探るため、同社は2020年9月、「NLP30」と銘打ち、技術を社会実装するためのパートナーを募った。
NLPで課題を解決したいと考えている企業は予想以上に多く、リリースの発表後、多くの方から引き合いを受けました。

なかでも目立ったのは、すでに社内外とNLPを活用してなんらかの取り組みを行っている企業です。
「一度、挑戦してみてダメだったのですが、これ実現できますか」と。
話を聞いてみると、みなさんBERTによるパラダイムシフト前のアプローチで試しているようでした。
そこで「できますよ」とお伝えし、我々が作っているものを見ていただくと、「ほかで『できない』と言われたけど、諦めなくてよかった」と驚かれます。
すでに具体的な展開も進んでいます。
戦略パートナーの一社であるSOMPOホールディングスとは、コールセンター領域での実証実験を7月から開始しました。
これは通話の音声データから、自動で要約メモを作るものです。
コールセンターの業務を見ると、電話対応に約40%、電話後の事務作業に約60%の時間がかかっている。事務作業の中でも、通話内容を連携するための要約メモ作りにかなり時間を取られていました。
ここを効率化するだけで、数億円のインパクトが出せます。

ほかにも、DX化の進むリーガル領域では、四大法律事務所の一つである森・濱田松本法律事務所とともに、契約書の情報抽出などの実用化を進めています。
ELYZAでは、このように核となる技術を作り、それを特定の市場で試しながら実際のサービスへの展開を考えています。
NLP30はそのセカンドステップにあたり、パートナー企業と一緒になって、本当にこの技術で業務効率化ができるのかを検証している段階です。
しかし、特定の企業だけが効率化できたとしても、インパクトは小さい。
次の段階では、日本全体に貢献するという意味でも、より多くの会社に提供できるようサービス化していく予定です。

日本トップクラスの人材と課題の種が集う
日本語AIエンジン「ELYZA Brain」の開発を成功させ、パートナーを得て社会実装にも取り組んでいるELYZA。
いま、NLPをビジネスとする企業は群雄割拠の様相を見せるが、同社の競争優位性はどこにあるのか。
いま、NLPをビジネスとする企業は群雄割拠の様相を見せるが、同社の競争優位性はどこにあるのか。
ELYZAの強みは、まず人材です。僕は2013年に大学院に進学してから、ずっと松尾研に関わり、現在も株式会社松尾研究所の取締役を兼任しています。
2017年当時は研究室でも、画像の研究が盛んだったのですが、その中でNLPに興味がある人たちを集める工夫をしてきました。サマースクールやスプリングセミナーでNLPの講座を企画し、運営や講師をしたり、勉強会を開いたり。
ELYZAの初期メンバーは、そうして集めた松尾研出身者が中心です。現在CTOを務める垣内弘太は僕がやっていた勉強会のメンバーですし、大規模言語モデルの研究開発を率いている中村朝陽は講座の受講生でした。
みんな最新の論文を読み、ディープラーニングの実装ができるスキルを備えた国内でも有数のプロフェッショナル。現在も、学術領域の先端人材との接点を持ち続けています。
もう一つの大きな強みは、NLPで解決できそうなニーズ群が50個近く集まっていること。
お客様はみなさん本当に真剣に考えていて、課題を抽出した上で相談してくれるんですね。
うちにはその変革の種が集まっているので、「おそらくこういうNLPのモデルがあれば、世の中にインパクトが及ぼせるのではないか」という解像度が、日本ではトップクラスに高いと自負しています。
さまざまなパートナーと協業しているためデータ量も現時点でかなり蓄積されており、今後もどんどん増えていく想定です。
もちろん、NLPの日本語モデルに大きく投資をし、当社ほど大規模な学習をしきったモデルは国内にわずかしか存在しない点にも自信を持っています。

僕たちが作ったELYZA Brainは汎用性が高く、「読む」「書く」「話す」という人間が行うタスクはだいたいできます。
たとえば、エントリーシートを読んで評価する、契約書の中から重要な条項を抽出するなど。
ELYZA Brainでできることの一部を体験してもらえるよう、文章要約のツールをデモとしてご用意したのが、「ELYZA DIGEST」です。
文章要約は、NLPで最も難しいタスクの一つです。
ある程度形式の整った書き言葉のテキストから一部を抜き出したり、不要な部分を削除したりする抽出型の要約はこれまでもありました。
しかし、「ELYZA DIGEST」では、音声認識で起こしたテキストなど、あまり整っていない文章からも要約が作れます。
まずは多くの方に気軽にデモで遊んでいただきながら、ELYZA Brainの実力を体感してもらいたい。
そして、ご自身の業務にどう活かせるか。浮かんだアイデアを、ぜひ我々にぶつけてください。
社会を大きく変える「未踏」の領域へ。新しいあたりまえとなるサービスを、ぜひともに生み出しましょう。

執筆:松本香織
写真:的野弘路
デザイン:小鈴キリカ
編集:樫本倫子
写真:的野弘路
デザイン:小鈴キリカ
編集:樫本倫子
株式会社ELYZA | NewsPicks Brand Design
