
2020/11/30
【LINE】AIの世界で「日本語」を後回しにしてはいけない
NewsPicks編集部 記者
コンピューターが「日本語」を自由に操れる日はやってくるのか──。
機械翻訳やチャットボットなど、人間が日常的に使う言葉をコンピューターに処理させる「自然言語処理」は、我々の生活にも浸透しつつある。
この分野は英語での研究開発が最も進んでおり、日本語は後れをとっているのが現状だ。
そんな中、11月25日、メッセンジャーサービス大手のLINEが、親会社で韓国検索大手NAVERと「超巨大言語モデル」の共同開発を発表した。
言語モデルとは、文の構造や、単語と単語などの関係性を定式化したもの。たくさんのデータから学習を行うと「この単語の次には、こういう単語がくるだろう」という予測をしてくれる。
こうした言語モデルの構築は、Googleなどのテック企業が積極的に行っている。
例えば、Gmailで数語(例「I look forward...」)打ち込むと、メールの文章(例「I look forward to hearing from you soon.」)を提案してくれる。ここに活用されているのが、Googleの言語モデルだ。
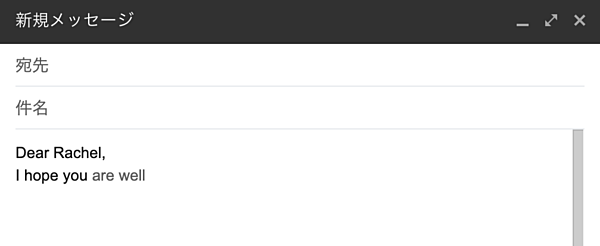
Gmailは、数語打ち込むだけで文章を補完してくれる
LINEは、こうした言語モデルを自社で開発し、日本語の自然言語処理を最先端のレベルへ持っていきたいと考えている。
LINEとNAVERがこのプロジェクトを立ち上げたのは、4カ月ほど前のことだ。
そのきっかけとなったのは、アメリカのトップAI企業OpenAIが2020年5月に発表した言語モデル「GPT-3」だった。
なぜNAVER とLINEに影響を与えたのか。まずはGPT-3の凄さについて理解しておこう。
