
AIの実用は「アカデミック×ビジネス」で切り拓く

NTTデータ | NewsPicks Brand Design
2018/9/21
第3次AIブームを牽引してきたのは、研究者を自社内に次々と集め、ビジネスの核に仕立て上げた北米のIT企業たち。AIの初動で後塵を拝することになった日本は、その原因を学術界(アカデミック)と実業界(ビジネス)の分断だとする評論もある。AIの実用が本格化するのは、まだこれからとの向きもある。
しかし、NTTデータによれば、着実に実用が進み、「第2ステージ」に入ったという。それにともなって、新しい課題も見えてきた。同社のAI&IoT事業部長 谷中一勝氏は、AIでこれから起こる課題に先回りして解決するには、「アカデミックとビジネスの融合」が不可欠だと強調する。同事業部の西村友昭氏も強く同意し、同社のAIにおける産学共同研究で中心的役割を果たしている。
「ビジネス」のNTTデータに賛同し、共同研究を進める「アカデミック」は、東京大学大学院准教授で、理化学研究所革新知能統合研究センター 深層学習理論チームのリーダー、鈴木大慈氏。ビジネスの最前線に立つ企業、AIの最先端に没頭する30代の気鋭研究者。これからのAIをどう洞察し、コラボレーションで何を果たそうとしているのか。
しかし、NTTデータによれば、着実に実用が進み、「第2ステージ」に入ったという。それにともなって、新しい課題も見えてきた。同社のAI&IoT事業部長 谷中一勝氏は、AIでこれから起こる課題に先回りして解決するには、「アカデミックとビジネスの融合」が不可欠だと強調する。同事業部の西村友昭氏も強く同意し、同社のAIにおける産学共同研究で中心的役割を果たしている。
「ビジネス」のNTTデータに賛同し、共同研究を進める「アカデミック」は、東京大学大学院准教授で、理化学研究所革新知能統合研究センター 深層学習理論チームのリーダー、鈴木大慈氏。ビジネスの最前線に立つ企業、AIの最先端に没頭する30代の気鋭研究者。これからのAIをどう洞察し、コラボレーションで何を果たそうとしているのか。
AIに「理論」を持ち込む
──鈴木先生は、東京大学大学院に身を置きながら、理化学研究所の深層学習(ディープラーニング)の研究チームのトップも兼務されています。鈴木先生の研究テーマは何ですか。
鈴木 「統計的学習理論」というもので、統計学をもとにAIの原理を探る理論を研究しています。簡単に言えば、AIの学習プロセスにおいてどのように学習が進み、最終的にどれくらいの精度で予測ができるようになるかを理論的に解明するものです。
AIに使われている多くの方法ではそれが解明されているのですが、いくつかの重要な方法、特にディープラーニングではそれが解明できていないところが多いんです。AIが答えを導き出すプロセスを解明する。それが私の研究の大きなコンセプトです。
──具体的な研究内容を教えてください。
鈴木 一つご紹介すると、「過学習」というものがあります。文字通り、AIの「学習し過ぎ」です。
──「学習し過ぎ」、ですか?
鈴木 機械学習ではデータの質と量が重要なのですが、分野によってはデータの内容が悪かったり、データそのものが少なかったりすることがあります。たとえあったとしても、入手にものすごく時間とお金がかかったりするケースもあります。
ですので、少ないデータでより正確に学習するための方法論を研究しています。そのための一つの手法が「過学習」の抑制です。学習データは、本質的な情報とは別にノイズを含んでいることが多々あります。ノイズを含んだ状態で学習モデルが作られると、AIが正しい答えを導き出せないケースがあります。
わかりにくいと思うので、画像認識を例にお話しますね。
たとえば、大量の画像データから犬が写っている画像を判別するAIがあったとします。犬の特徴をAIに学ばせて犬かどうかを判断すればいいのですが、犬とともに写っているなんらかの物体、例えば犬小屋などを判断材料にしてしまい、本当は犬じゃないのに、犬だと認識してしまうことがあります。
犬そのものではなく、ほかの情報に引っ張られて判断してしまい、犬小屋をみて犬といってしまったりする。つまり、学習し過ぎてしまうんです。
過学習は、画像のような高次元データ、つまり情報量が多く複雑なデータのほうが起こりやすい。画像で言えば、1万ピクセルのデータよりも100万ピクセルのデータの方が、情報量が多いので、学習するための材料が多い、つまり学習「し過ぎてしまう」領域も広い。
画像の他にも遺伝子データや金融データなど多くの高次元データが存在します。ですから、私は高次元なデータを対象に、過学習を防ぎながらより少ないデータで正確な答えを導き出すための理論を追求しているのです。

谷中 AIの理論研究はアカデミック分野の話だけではなく、実際にAIを実用しようとすると必ずぶつかるテーマです。だから、鈴木先生のアプローチは、ビジネスの場でも非常に価値がある。

AIをビジネスに適用する上では、なぜその答えが正しいと判断したのか根拠を説明できる必要があります。実際、結果が正しいのか不安を持つお客さまもいらっしゃいます。いわゆるAIのグレーボックス化、ホワイトボックス化が求められています。
理論的に証明できるようになると、ビジネスでの導入が一気に加速します。ですから、鈴木先生の研究の重要度は非常に高い。
西村 2012年にディープラーニングが脚光を浴びて以降、話題の中心は「何ができるか」でした。しかし、この数年は、ディープラーニングの理論的な裏付けをしようという動きが盛んになってきています。

──分からないのに、使っている。たしかに、ビジネスでは不安ですね。この研究におけるブレイクスルーは見えているんでしょうか。
鈴木 ブレイクスルーがあるか、それもまだはっきり言える状況ではありません。少しディープな話になってしまいますが、おつきあいください(笑)。
今ひとつ分かってないのは、学習する上での「局所最適解」です。ディープラーニングなどの機械学習では、データにモデルを当てはめるということをします。そして、「当てはまりの良さ」を測るんですね。
それで、学習を進めることで、当てはまりをどんどんよくしていく、つまり誤差を小さくしてくんです。ニューラルネットワークの学習は、この絵全体を見ずに、自分のいる場所の少し隣だけを見ながら誤差がより小さいところを探す作業なんですよ。

普通に考えれば、そこそこいいところを見つけると学習が途中で止まってしまうはずなのですが、 ディープラーニングの場合はなぜか止まらない。ちゃんと次の当てはまりがいい場所まで行けるんです
谷中 神の目が、どこかにあるようですね。
鈴木 本当は難しいはずなんですが、なぜかできてしまっている。その理由もよく分かってない。このようにディープラーニングの世界にはまだ解明できていないことがたくさんあるんです。
──こうした研究は、国際的に進められていると考えていいでしょうか。
鈴木 そうですね。実は歴史は古く1970年代から1990年代にかけても盛んに研究がされていました。しかし、ニューラルネットの実応用研究が下火になるにつれ理論研究もそれ以降進展がみられなくなりました。
それがディープラーニングの登場により、その重要性が再認識されています。こういう問題へのアプローチには理論、数学が必要。統計と最適化の周辺にある、いろんな知識が必要ですね。みんなで知識を総動員して、世界のAI研究者が頑張って研究している状況です。
第一人者が理論研究の道へ進んだ理由
──鈴木先生は、理論的な研究の必要性に気づいて国内でいち早く取り組み始めてますね。機械学習研究の第一人者である、理化学研究所革新知能統合研究センター長の杉山将先生から、深層学習理論研究のリーダーとして鈴木先生に声がかかったと聞きました。鈴木先生は、どうしてこの研究を始めようと考えたんですか。
鈴木 遡ると、中学生の頃になりますね。ちょうどWindows 95が出て、これからはAIの仕事だなと思ったんです。パソコンが身近になってインターネットも普及するという実感が湧いてきて次はAIだな、と。
コンピュータ前提の社会でキラーアプリケーションとなるのは人工知能だと直感したんです。ですので、中学生の時にAIに関する何らかの研究者になるつもりでした。
AIの理論研究に興味を持ったのは、大学2年生ぐらいでしょうか。AIには数学的なアプローチが必要だということは、世界的には研究者たちの間で当然とされていましたが、メジャー感はないテーマでした。でも面白いのは、GoogleやAmazonが圧倒的な物量で研究している世界に対して、1人でも勝負できる。それが理論研究なんです。
──世界のビッグプレーヤーを相手に戦える分野だと?
鈴木 彼らは確かにすごいニューラルネットワークモデルを持っている。莫大な投資によって巨大な「計算機」もある。でも、深層学習理論については、あまり研究をしていません。理論なら、あくまで脳での勝負で勝てる可能性があります。

学術とビジネスの距離が近いのがAI
──NTTデータとしては、自前で研究を進めようとは考えなかったのでしょうか。
西村 鈴木先生とは、昨年度から共同研究を進めています。NTTデータはこれまでも、自社でソリューションを開発・提供してきましたが、この分野は、発展のスピードが著しく速い。
一企業で最新動向を追い続けるのは効率的ではないですし、トップの研究者と一緒に研究することで、最新の研究成果をいち早く手に入れられます。さらにそこから自分たちに必要なものを生み出すことができます。
谷中 AIは、アカデミックとビジネスの距離が近い分野なんです。例えば研究者が出した論文を見ながら、企業内の技術者が新しい技術を数日で実装してしまったりする。論文を見ながらエンジニアが何かを実装するって、あまりない現象だと思います。AIこそ、アカデミックとビジネス業界がシームレスにつながるべき分野だと感じています。
──鈴木先生はなぜ企業との共同研究を始めようと思ったのですか。
鈴木 研究者は、自分たちの成果を論文にして発表していくために研究している側面があります。ただ、研究は研究者の中だけ、アカデミックの世界だけで終わらせてはならない。
何らかの形で社会に還元するべきです。その点では学術業界に身を置く私だけでは限界があり、社会でAIを実装しているNTTデータとのコラボにはメリットがあると考えました。実際に、昨年からの共同研究による成果もでてきています。
NTTデータと聞いて、通信やインフラ系のシステムに強いというイメージだったので、正直に言って、一緒にAIに取り組めるとは思っていませんでしたが、共同研究を進めていくと、かなり深いところまで突き詰めてビジネスに適用するための施策に力を入れている。これくらい体力のある会社が将来の課題を考えて動き出しているのは、日本にとっていいことだと感じました。

自動運転は現在の手法では世界に広がらない
──ビジネスにおいて今、AI活用における最先端の課題とは何ですか。自動車業界は自動運転などAI活用に先進的だと思うので、自動車業界の最新事情を教えてください。
西村 日本では自動運転を肌に感じることはまだ少ないですが、世界を見るとすでに実用化に向けた動きも始まっていますよね。欧州では昨年すでにAudiが高速道路向けの自動運転を開発し、北米ではGoogle系のWaymoが自動運転タクシーのサービスを今年度中にアリゾナ州で開始すると発表しています。
ところが、これらの自動運転はいわゆる“完全自動運転”ではありません。自動運転のレベルは1から最高の5まで定義されていて、どれもレベル4以下なんです。レベル5との違いは、自動運転が可能な環境に制約があること。例えば速度や混雑状況、地域、ルートなどが限られている。限定された環境においてのみ自動運転ができるのが、現状です。
──確かに、どこでも走れる自動運転車はない。
西村 今、既存の自動車メーカーも含めてさまざまなプレイヤーによってモビリティ業界の大変革が起きていて、莫大な投資をして開発していますよね。ビジネスにしようと思ったら、投資を回収できる戦略が必要です。
今の自動運転車は高級モデルから展開している。それは開発コストがかかっているからですが、これでは一般には普及しません。より多くの人が利用できるようにするためにはハードだけでなく、AIでもコストダウンが必要なんです。
2018年7月にWaymoが自動運転開発のために、それまで約800万マイル(約1300万km)の走行実験をしていることを発表しました。
北米と日本やアジアでは、歩いている人の様相も違えば、格好も違うし、道路の広さも舗装の仕方も違います。そういう異なる環境下でもAIが期待どおりに動作してくれる保証はありません。各地で走れるように、また時間もお金も同じように投資できるでしょうか。
これでは時間がかかるし、実現しても高コストな車になってしまいます。ディープラーニングによりこれまでできなかったことができるようになった。今は自動運転による「利便性の追求」が進んでいますが、次は「利便性、安全性、生産性のバランス」を取ることが必要になるはずです。

──共同研究のポイントを教えてください。
西村 具体的な例をあげると、「学習データをいかに効率的に整備するか」というテーマに取り組んでいます。ディープラーニングの学習には大量のデータが必要です。自動運転に適用する場合、学習データの整備にいくつかのハードルがあります。
収集したデータは大量にあるが、どれを学習データとするか、また学習するための正解フラグをつける作業に膨大な時間がかかってしまう。北米など特定地域で撮影した画像データを、他の地域向けのモデルの学習に適用したい。事故が起きやすい状況などレアなシーンは、そもそも収集が困難で学習データがつくりにくいなどです。
実際には、これらの問題が同時に起こります。こうした複雑かつ複合的な問題を鈴木先生と一緒に研究し、解決の糸口を探っています。
鈴木 アカデミックな研究でも、ディープラーニングのこれらのテーマに対する研究は始まったばかりで、まだそれぞれの問題を別々に解決しようとしている段階です。NTTデータと共同研究をすることで、こうした実際に社会で起こりうる問題にいち早く取り組むことができます。
谷中 データ整備の問題は、自動運転だけに限った話ではありません。例えば、メンテナンスのために設備の異常を画像認識で検知したい場合に、学習のための画像データが不足していたり、商品別の販売量を予測したい場合に過去データが不足していたりなどで、予測モデルの精度がでない問題が起きます。ディープラーニングを活用する場合は、必ずぶつかる問題でそれだけに重要なテーマだと考えています。

──共同研究の成果を教えてください。
谷中 IoTが進展してくるとデバイスにどうAIを埋め込んでいくのかが課題になります。IoTのデバイスって、CPUやGPUなどの計算リソースが潤沢でない場合も多いですよね。
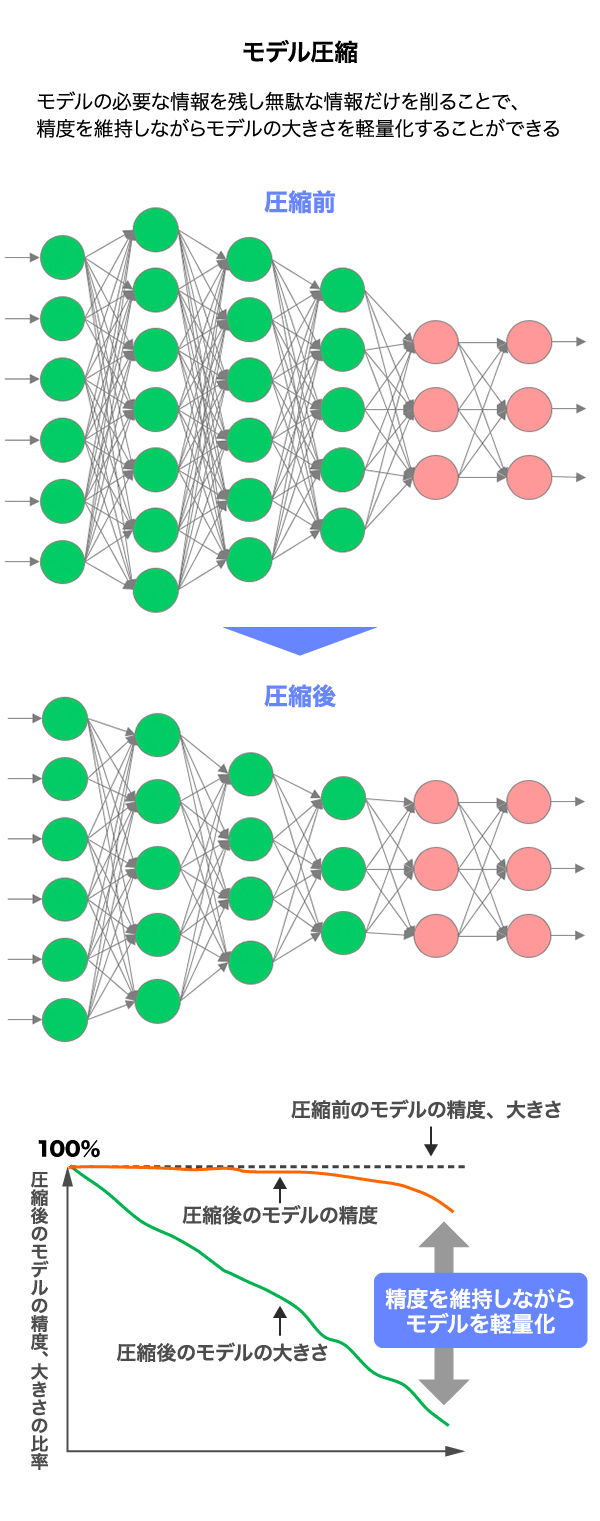
AIのモデルをよりコンパクトにする必要があります。そこで一度、学習したAIのモデルを軽量化するために、ニューラルネットワークを圧縮する技術開発が必要になってきます。
鈴木 「モデル圧縮」と言うんですが、先ほどの過学習の問題と関係があって、すごく興味深いものです。圧縮は必要な情報は残しつつムダな情報を削ること。AIの予測には必要のないムダな情報だけを削るため、精度を下げずにモデルを軽量化することができます。
西村 軽量化することで必要な計算リソースも節約でき、コストダウンにもつながります。我々の共同研究では、なぜ圧縮できるか、どこまで圧縮できるかという理論的な裏付けについても踏み込んでいます。
谷中 モデル圧縮だけでなく、先ほどお話しした効率的な学習データ整備、またディープラーニングのホワイトボックス化は鈴木先生との共同研究のテーマです。いずれの研究も、AIを実用化、大衆化するには欠かせない研究だと確信しています。
未来の課題を見越して準備するのが使命
──AIをビジネスに生かそうとする動きは引き続きあると思いますが、最近の企業のAIに対する取り組みはどこまで進んでいるんですか。
谷中 大手企業ではAIやIoTの活用を推進するために、デジタルトランスフォーメーションを指揮する「デジタル○○部門」という組織ができ始めています。そこがまず最初に考えるのがデータ活用ですね。そうするとアナリティクスAIを使ってみたいけど、でもそれをできる人がいない。データサイエンティストがいないんですね。
そこで我々からデータサイエンティストを割り当てて、AI技術活用の体制を支援するというご依頼をいただくことが多いですね。これは、ちょっと試してみるPoC(*)の域を脱して、継続的な取り組みが始まっていることを意味します。
*PoCとは:Proof of Conceptの略。新しい概念や理論、テクノロジが実現可能かどうかを検証するための簡易的な試行
──1、2年後に、AI活用はどの程度進んでいると感じていますか。
谷中 AIの技術は、だいぶ使いやすくなってきました。ですから恐らく、メンテナンスの部品在庫をこれだけ減らせた、顧客のリテンションが図られた、広告効果が上がったといった効果が、机上ではなくROIとして如実に数値となって結果が現れてくるかと思います。

──実利を得て、もうワンステージ上がるタイミングになる。
谷中 もうそのサイクルに入っているかもしれないですよね。その第2ステージのときに、課題になるものを、鈴木先生と一緒に最先端の研究をすることで準備しています。
お客さまは課題の設定が尽きないから、また次を求めるでしょう。コモディティになると、みんな使い始めて競合との差異が図りにくくなる。だから私たちも、常に1歩先、2歩先を進めておく必要があるということです。
先を見越して課題を整理し、解決策を提示していくのは、私たちIT企業の使命だと思っています。
西村 自動運転だと、最先端のAI企業にもまだ解決できてない課題がたくさんあります。利便性の追求については、北米などの海外勢が先行しています。でも、安全性や生産性とのバランスについては、まだまだこれから。日本は、そういうテーマは元々得意です。だから日本にも十分勝機がある、そう考えています。
テクノロジーを一部の企業や人だけでなく、可能な限りすべての人に提供すること、それも我々の役割だと思っています。
鈴木 そのためにも、世界に勝てる理論研究を着実に進めたいですね。
(取材・編集:木村剛士、構成:加藤学宏、撮影:森カズシゲ)

NTTデータのAIソリューションの具体的なサービスや先進事例をまとめた特設サイトも合わせてご覧ください。こちらからお読みいただけます。
<関連記事>



NTTデータ | NewsPicks Brand Design
