
Datadog の記事を書きたいって言って3億年が経ちました (前編)

わんわん!
Showcase Gig でテーブルオーダーサービスのインフラ、バックエンド開発を担当しています赤嶺 (@kazz187) です。みなさんは Datadog 使ってますか?
テーブルオーダーサービスのモニタリングに Datadog を導入して約2年が経過しましたので導入の過程を振り返りつつ、使用感をお伝えできればよいなと思い、記事を書きます。
Datadog の便利なサービスたち
Datadog といえばモニタリングサービスで有名なのですが、個人で使うには高すぎますし、実際に使ったこと、導入したことのある方って実は少ないのでしょう。
私も弊社に入社するまで触ったことがなく、メトリクスを拾ってきれいなグラフを見せてくれるサービスなんだろうな?ということをぼんやり思い描く程度の認識でした。
実際に触ってみると、その認識は Datadog のほんの一部の魅力でしかないことに気がつきます。 個々のモニタリングサービス(メトリクス、ログ、分散トレーシングなど)がタグによってひとつに束ねられ、サービス開発/運用へ刺さる強力な武器になります。
Datadog Logs
まず、最初にびっくりしたサービスは Datadog Logs です。Logs は名前の通りログを集約するサービスです。
私たちの開発しているサービスはプラットフォーム戦略を取っており、複数のサービス群から成り立っています。マイクロサービスと言えるほど細かく分割してはいないのですが、それでも複数の AWS アカウントにまたがって運用しています。
Logs 導入以前に不具合や障害が発生した際には、各サービスの AWS アカウントにログインし CloudWatch Logs でログを確認するということを地道にやっていました。 発生時間から問題のエラーログを絞り込むのですが、各アカウントでひたすら検索をかけてサービス間のつながりや障害の発生場所を調査するという徒労続きで、貴重なエンジニアの時間を大量に浪費していました。 CloudWatch Logs はロググループが細かく分かれていて、複数のサービスのログを並行して追っかけるのには向いていません。
そこでメトリクスの収集のためにすでに使っていた Datadog の Logs にすべてを集約することにしました。 複数のアカウント、ロググループに分かれていたログたちをひとつの場所に集約するのですからルールを決めなくてはなりません。そのときに気を付けたことを紹介します。
ログを集約するときに徹底したこと
1. どこのログなのかを明記する (env, service, task, role)
2. どのリクエストに対するログなのかを明記する (transaction_id)
まず、どこのサービスから出たログなのかをはっきりさせるため、ログに対するタグ付けを徹底しました。(Datadog は1つのログに対して key/value 形式でタグを付けることができます。) 環境名、サービス名、タスク名、ロール名 (Web, App, Log など)を付与することにしました。
弊社は AWS Fargate でサービスを運用しているのですが、2019年末に登場した firelens を使い標準出力に吐かれたログをサイドカーである fluent-bit のコンテナに流し込んでそこから Datadog Logs へと転送しています。 (いつか AWS Fargate 運用術の記事も書きます。)
先程紹介したタグたちを下記に紹介する fluent-bit の設定ファイルですべてのログに一括で付与しています。
[OUTPUT]
Name datadog
Match api-app*
Host http-intake.logs.datadoghq.com
TLS on
apikey ${FLUENTBIT_DD_API_KEY}
dd_service ${FLUENTBIT_DD_SERVICE}
dd_source go
dd_tags task:${FLUENTBIT_DD_TASK},role:app,env:${FLUENTBIT_DD_ENV}dd_service にサービス名を、dd_tags にそのほかのタグを指定しています。
これらのタグ群をすべてのログに付与することにより、今まで必死に複数の AWS アカウントを渡り歩いて集めていたログを、簡単な検索クエリで自在に絞り込んで閲覧できるようになりました。
次にどのリクエストに対するログなのかを示す transaction_id です。 (後に分散トレーシングで使われる dd.trace_id になりました。) 外部へ公開している API のエントリポイントでリクエストごとにユニークな ID (transaction_id) を払い出し、バックエンドのサービス群すべてへ引き回してログへ付与するようにしました。 このことにより、問題のエラーログが見つかったときそのログにある transaction_id を検索することによって、前後のログを複数サービスにまたがって抽出できるようになりました。

ログにこのように transaction_id を埋め込むと、ログから検索できます。 (Datadog で attribute を検索するには facet として事前にインデクシングしておく必要があります。)
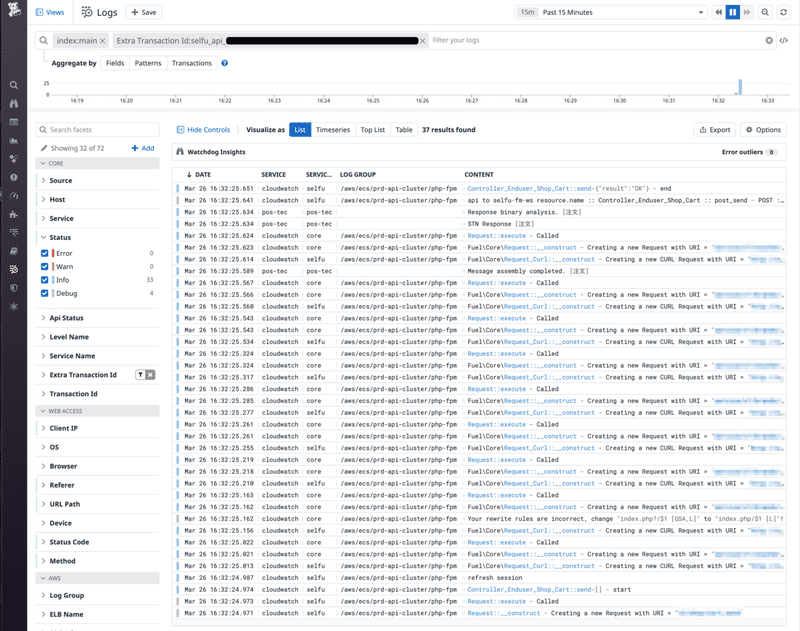
transaction_Id を用いて検索すると、1リクエストにおける複数サービスのログを時系列順に並べて閲覧できます。
これらのログ規則により、障害対応にかけるスピードが飛躍的に早くなりました。
Datadog Logs にはこれらの検索をサポートする UI がそろっています。 検索結果のリンクをみんなで共有してエンジニア一丸となって障害対応へアタックできるようになりました。
エラーログの検出
エンジニアはサポートに飛んでくる連絡よりも早く不具合や障害に気付かなくてはなりません。 そのためにはリアルタイムなエラーログの検出を日々行う必要があります。
これも Datadog Logs を使うと簡単に実現できます。
Datadog Logs には Status というカラムがあり、ログレベル (FATAL/ERROR/WARN/INFO など) を入れることによりログを分類できます。 これらを設定しておくと、 status:error と検索するだけでエラーログを抽出できます。
アラートの設定は Datadog Monitors というサービスで行います。 先程設定したサービス名と併せてエラーレベルのログを検索し、各サービスの Slack Channel にアラートを飛ばすことができます。
導入当初は膨大な量のエラーログが飛んできましたが、約半年かけて地道に不具合を修正したりログレベルを調整することで今では安定して不具合の検出ができるようになりました。
次回は Datadog APM 編
導入初期に Datadog Logs を使うことを決めて以来、障害対応のスピードや、日々の開発、特に各サービスの結合時の動作確認のスピードがびっくりするほど早くなりました。 実際に吐かれたログを元に皆が会話するようになるので、問題に対して憶測で話すことが少なくなり、解決まで一直線に進むことが多くなりました。
それでもまだこのときの私達は Datadog の本当の凄さに気付いていません。 このあと Datadog APM を導入することによって、劇的にサービスのクオリティが改善していくことになります。
ではまた1億年後、お会いしましょう。
Showcase Gigで急成長するプロダクトを一緒に作る仲間を募集しています!
この記事が気に入ったらサポートをしてみませんか?