近年におけるAI(人工知能)の発展は著しい。しかしその一方で、企業における実際の業務にAIを活用する取り組みは、あまり進んでいないのが実情だ。AIの活用を阻んでいる「壁」と、それを乗り越える方法を解説する本連載。第2回は学習データの不足を解決する手法、「秘密分散学習」を紹介する。
高精度なAIモデルを作成するためには、学習データに関する十分なの質(特徴の種類)と量(バリエーション)が欠かせない。このため単独組織のデータだけでは質や量が不足する場合、複数の組織のデータを統合してAIモデルを作成するのが理想的だ。しかし一般に情報機密性の観点から、組織をまたいでデータを流通するのは困難である。
こうした課題に対応するべく、情報を秘匿したまま大規模データセットに対するモデリングを可能にする秘密分散学習技術という分野の研究が盛んになっている。
異なる組織のデータを安全に組み合わせて学習
複数の組織の間でデータを組み合わせるパターンは、大きく2つが考えられる。
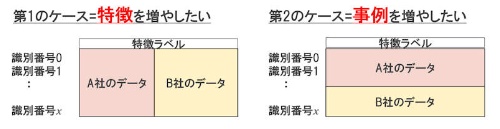
第1は「A社だけではデータの特徴が不足しているが、他社のデータと組み合わせると十分な特徴を得られると期待できるパターン」で、これはデータを「横に結合」するパターンと表現できる。
第2は「A社だけではデータが真の母集団と比べて偏っているが、他社のデータと組み合わせると真の母集団を近似できるパターンで、これはデータを「縦に結合」するパターンと表現できる。
2つのパターンとも共通して、単独組織のデータセットでは不足があることを意味している。ここで秘密分散技術を適用すると、他組織のデータを使って自組織のデータの不足分を補えるようになる。「医療機関」と「保険会社」を例に、シナリオを説明しよう。
特徴を補うか、件数を補うか
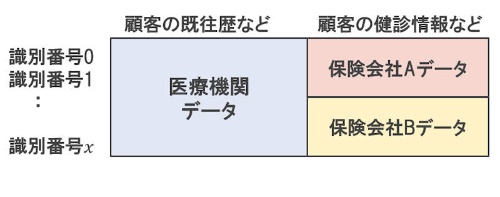
まずは「横に結合」するパターンだ。医療機関と保険会社では、同じ患者について異なる特徴を持ったデータを所有している。異なる業種(セグメント)に所属する組織のデータを統合することで、例えばある人物に対する発症予測モデルの精度を高める、といったことが期待できるようになる。
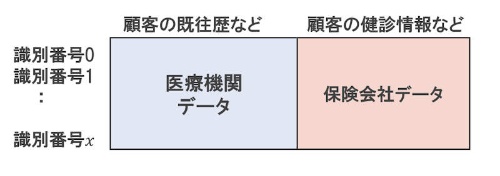
続いて「縦に結合」するパターンだ。これは、保険会社同士、医療機関間同士といった具合に、同じセグメントにある組織同士でデータを統合するケースだ。これによって、未知の人物に対するモデルの汎化性能を高めるといったことが期待できるようになる。
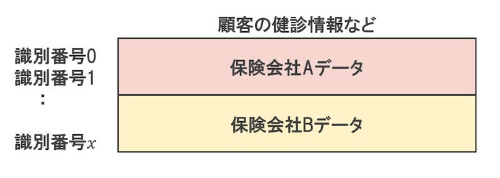
縦と横を同時に結合するパターンもある。1つの医療機関に対し、複数の保険会社のデータを統合するというケースだ。両方のパターンで得られる効果が同時に期待できる。