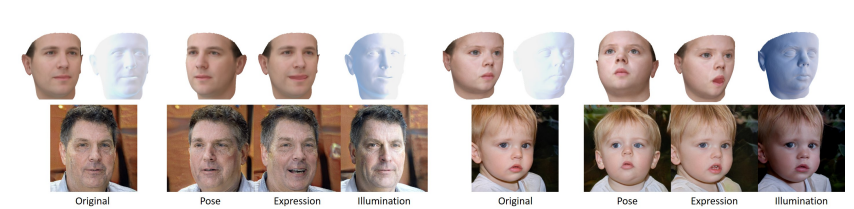
「自己監視で学習するため、追加の画像や手動のアノテーションは必要としない。」 もしかしたら誤訳でしょうか。英語だとself-supervised learning、日本語だと自己教師学習だと言いたかったのだと思います。 この技術の売りは、最後に書いてある「微分可能レンダラーを用い、算出した差分を画像領域における損失として定義している。」という点だと思います。深層学習は、微分可能な表現にするとニューラルネットワークの最適化フレームワークの中に組み込みやすいです。逆に、できないときは強化学習などを用います。
マイニュースに代わりフォローを今後利用しますか