Uber徹底研究 -データ取得効率化編 ベイズ最適実験計画法-

「今あるデータを使って何かできないか?」
既に、この問いに対して様々な解決策が出されてきました。
しかし、「どのようなデータを取得していくべきか?」という問いには答えられるでしょうか。しかも、取得していくデータが施策や実験を伴うものであれば、当然ながら時間やお金がかかるため、効率良くデータを取得していく必要があります。
ここで、Uberが提唱するのは、
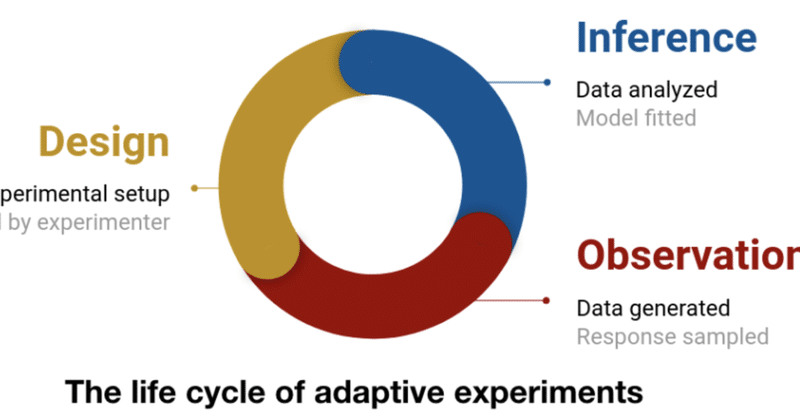
Design→Inference→Observeのサイクルです。
つまり、データを取得するための設計(Design)をし、最適な方法を推論し(Inference)、結果を観察する(Observe)ことを繰り返し、より効率よくデータを取得するものです。
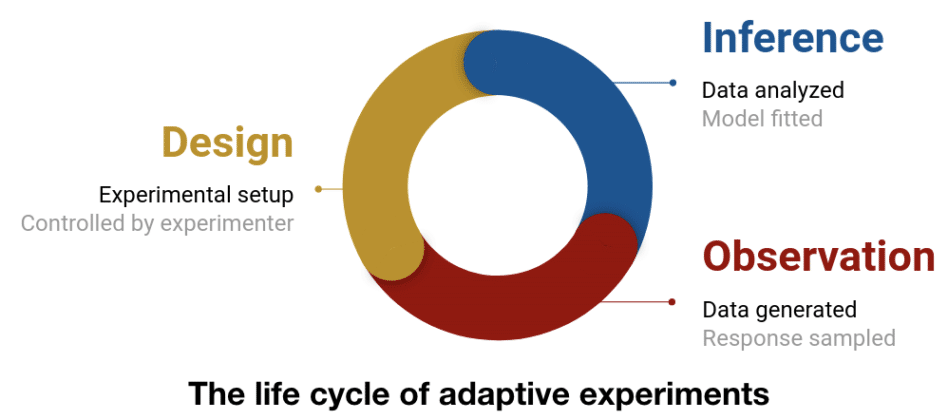
設計:実験で制御可能な部分を設定
観察:実験を行い、データを取得
推論:モデルを更新するため、収集したデータを分析
それでは、このサイクルを具体的にどのように実行していくのでしょうか。
そこで、今回重要になるのが実験計画法という考え方です。
まずは実験計画法の基本的な考え方から紹介し、
・従来の実験計画法の課題は何か
・その課題をUberはどのように乗り越えようとしているのか
を紹介していきます。
[過去のUber徹底研究シリーズ]
・Uber徹底研究 -ビジネス概要編-
・Uber徹底研究 -UX改善編-
・Uber徹底研究 -ゲーミフィケーション・行動科学編-
・Uber徹底研究 -MaaSを支えるデータサイエンス編-
・Uber徹底研究 -「続き」MaaSを支えるデータサイエンス編 レコメンド-
・Uber徹底研究 -因果推論によるマーケティング最適化編-
実験計画法とは何か
例として、ラーメンを作るケースを設定し、美味しいラーメンを作るために麺を茹でる温度や時間を考えます。
・どのくらいの温度
・どれくらいの時間
が最適かを考えるために、
温度を10パターン、時間を10パターンの合計100パターンの実験を計画します。
このように、「取り上げる対象についての結果と、それに影響するであろう要因との関係を調べるために、時間面、経済面などの制約を考慮しながら、計画的な実験によりデータを得て、それらを解析し、有益な情報を見出す一連の方法」のことを実験計画法と呼びます。(「統計学実践ワークブック」より)
実験計画法は、他にも、広告、マテリアルインフォマティクス、生物の実験など様々な分野で使用されます。
古典的な実験計画法では、上記のラーメンを作る時のように全ての変数を網羅的に試し、その上でどのパターンが最適なのかという絨毯爆撃的なものでした。
ただし、この方法では、変数の種類が多い場合(1000変数×100パターン等)には実験データを獲得するために時間や費用がかかります。たとえばUberではUX向上のための実験を設計する際に、数100もの設計パラメータや高次元でノイズの多いデータが存在し、また設計をリアルタイムで適応させる必要があります。
したがって、実験データを効率良く取得していくために、従来の実験計画法をアップデートさせた新たな方法が必要でした。
ベイズ最適実験計画法(BOED)の登場
そこで、注目すべき方法が、今回紹介するベイズ最適実験計画法(BOED)です。BOEDは限られた実験資源を効率的に利用するための方法です。
テクニカルな説明としては(一旦スルーして頂いて大丈夫です)、BOEDはデザインdと関連のあるパラメータθの特定の値を与えられた実験結果yの予測モデルp(y|θ,d)を構築し、実験から得られるθの期待情報利得(EIG:Expected Information Gain)を最適化するデザインを選択するというものです。
少し分かりにくいかと思いますので、具体的な例を使って説明します。
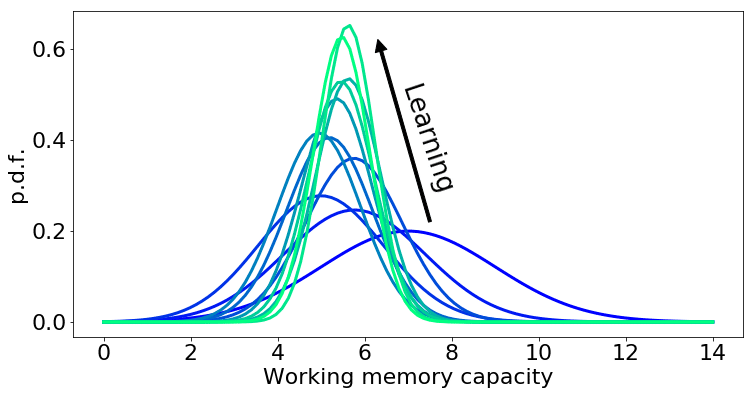
今回使用する例は、脳のワーキングメモリの機能を測定する実験です。人が短時間で覚えられる数字の数を特定するため、5~9個程度の数字を使って、人がどれくらい数字を覚えられるかを実験します。
何回か実験を繰り返しますが、BOEDでは前の実験結果を使用して、後続の実験で最適な設計ができるように計算をします(この部分が上記の「実験から得られるθの期待情報利得(EIG:Expected Information Gain)を最適化するデザインを選択」に該当します)。
そして、計算と実験を繰り返し、効率良く有益な実験結果を取得していきます。具体的な変化の様子は下のGIFをご覧ください。

有益な実験計画とは何か
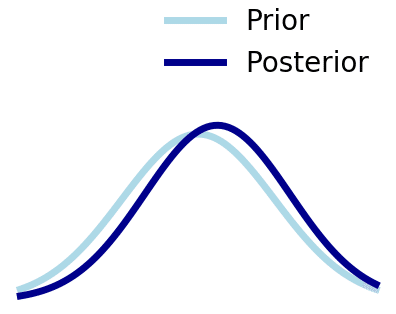
最適な実験計画をしたとしても、必ずしも有益な結果が得らえるとは限りません。例えば、下図の例では、事前分布(Prior)と事後分布(Posterior)がほとんど変わりません。そのため実験前後で得られる結果も変わりません。
一方で有益な実験計画は、事後分布が事前分布よりも尖った形になっているものです。先ほどのワーキングメモリの例に沿うと、人が覚えられる数の個数は「だいたいこの辺り」という確度が高まっている状態になっていれば、有益な実験計画と呼べます。
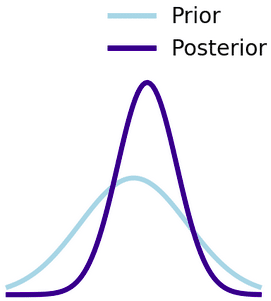
ここでは、新しいデータを獲得した結果として不確実性が減少しています。この不確実性の減少がポイントです。
BOEDでは、実験を重ねて蓄積したデータを次々と使い、次の実験を計画していきます。この方法により、最も不確実性が残っている場所を特定するための情報を獲得し、最適な実験計画を行います。
EIGの推定方法を提案
ここで、あまり触れずにいた実験計画スコアのEIGについて、実はこのEIG、推定することが難しいのです。EIGを推定する際には、従来の方法であるモンテカルロ法ではBOEDに適応できませんでした。テクニカルには、NMC(Nested Monte Carlo)の収束が遅くなってしまうことが問題でした。
そこで、UberはEIGの推定のための4つの方法を提案しました。詳細についてはこちらの論文を参照ください。
また、Pyro(Uberの開発した確率的プログラミング言語)を使ったEIGの推定の実装例もあります(参考文献参照)。
実際にUberが提案した方法を試すと、以下のように試行を繰り返して事後分布が尖ってくる様子が見られます。
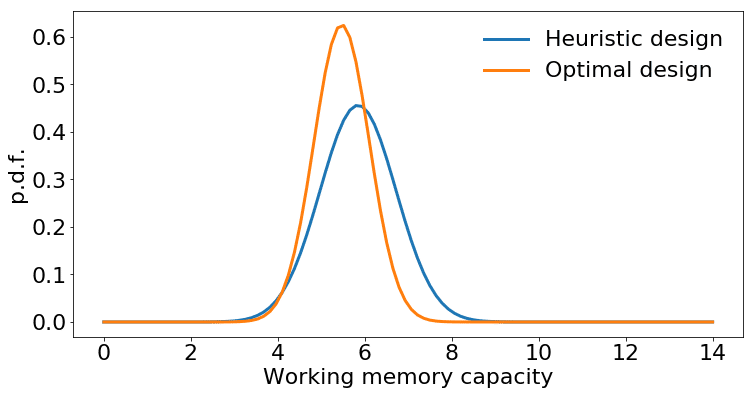
さらに、BOEDによる事後の不確実性は、人間が選択して設計した場合よりも低くなっていることが分かります。
データの獲得方法も最適化する時代へ
「どのようなデータを取得していくべきか?」
最初に設定した問いに対して、Uberの最適なデータ取得の方法を紹介してきました。現在では、どの組織でもデジタル化によって、業務をLeanにしていくことが求められる中、今回紹介したBOEDにより効率的にデータ取得が可能になります。
mROI最大化の取り組みは良く聞きますが、データ取得の効率までも最大化している企業はほとんどないと思います。
究極的な効率を追求するUberが今後どこまで進化していくか、今後も楽しみです。
参考文献:
・Announcing a New Framework for Designing Optimal Experiments with Pyro
・Variational Bayesian Optimal Experimental Design
この記事が気に入ったらサポートをしてみませんか?