
「AIの中身はブラックボックス」なんて言わせない

日本IBM | NewsPicks Brand Design
2018/11/26
もし、あなたが住宅ローンを申し込み、AIが「40% 許可」と回答したら納得できるだろうか。なぜ許可のパーセンテージが低いのか、何を根拠にしているのかを知りたくなるだろう。AIがビジネスに浸透するにつれ、AIが導き出した判断に疑問符がつくことが生じてきている。AIが出す結果の信頼性や説明可能性を高める取り組みについて、日本IBMのW&CP事業部ワトソンソリューション担当の田中孝氏に聞いた。
AIの3つの活用領域
リビングには家電を操作できるスピーカーが定着し、コールセンターでは問い合わせにチャットボットが自動応答し、医療機関では診断画像から病変を検出するなど、AIは徐々に社会に浸透してきている。
ビジネスにAIを導入する際には、自社の業務に特化したAIを「育てる」ことが必要になる。子どもを教育するように、保険会社なら契約履歴、医療機関なら診断画像など、AIが判断するのに必要なデータをAIに与えることで学習させる。どれだけ賢くなれるかは、どれだけ質の良いデータを、より多く与えられるかにかかっている。
中には、開始直後はうまく実力を発揮できないAIもある。本番前にデータを学習し、モデルを磨きあげてはいるが、いざ本番デビューすると、想定したとおりの質問がユーザーから来ないこともある。自然言語やコミュニケーションといった要素が複雑に絡み、正しい答えを出せずに苦戦する。しかし、実践を積み重ねることで、精度が高めてられていくのだ。
ところで、いま企業でAIはどのように活用されているのか。「AIに何をやらせるのか。その領域は、『照会応答』『探求発見』『意思決定支援』の3つに大別できます」と話すのは、最近まで顧客の現場でIBM Watsonの導入を支援するソリューションアーキテクトを務め、現在はテクニカルセールスを担当している日本IBMの W&CP事業部 ワトソンソリューション担当、田中孝氏だ。

日本IBMの W&CP事業部 ワトソンソリューション担当 田中孝氏
照会応答は、質問に対する最適な回答を予測し提示するもの。
探求発見は、大量のデータからその関連性を見いだし何かを洞察するもの。
そして意思決定支援は、ビジネスにおける何らかの判断を手助けするもので、例えば保険やローンの申請認可や社員の採用など、人間が「OKかNGか」を判断する業務で、判断の指針となる情報を予測し提供する。
いずれにしても学習したデータから答えを導き出すところは共通しているものの、照会応答だけではなく探求発見や意思決定支援へと、次第に難易度の高い質問に応じられるように高度化する。それによって、ビジネスの多様な要請にも応じられるようになり、ビジネスへの貢献度も高まっていく。
AIのブラックボックス化が課題に
そうした中でいま、「AIのブラックボックス化」「AIバイアス」と呼ばれる課題が生じてきているという。
「AIは『NG』と予測したが、YESではないのか」「NOと判断した根拠は何なのか」「年齢や地域などによって判断に偏りがあるのではないか」と、AIをどこまで信じていいのか疑問視するケースが起きるようになってきた。これは、前述した照会応答、探求発見、意思決定支援のうち、特に意思決定支援でAIを活用する際に問題になると田中氏は言う。
AIの予測が正しいかどうかを検証するのは、容易なことではない。一般的にコンピュータ処理は、プログラムで計算や処理のロジックを定めているため、答えが正しいかどうかは明確に検算や検証ができる。しかしAIは、多層のニューラルネットワークを活用し、データの特徴量をそれ自体で導き出して予測を行うため、そうはいかない。それゆえに、AIのブラックボックス化や回答の正当性が疑われることになるのだ。
それではAIが導き出す回答が正しいかどうか、それをどのように測定すればよいのだろうか。田中氏はAIの評価基準として、「精度」と「公平性」の2つを挙げる。

AIの評価基準「精度」と「公平性」
精度は、予測の正確さの度合いだ。例えば、胃カメラの診断画像から胃がんの可能性を予測するAIであれば、胃がんが「ある」のか「ない」のか、予測の正答率が精度ということになる。
一方の公平性は、年齢、性別、地域、人種などの属性によって、予測に偏りがないかということだ。例えば、自動車保険の申請で、年齢や居住地域によって申請者に不利な回答が出たとしたら、公平性を欠くことになる。田中氏は「近年アメリカでは、人種などによってAIの予測が偏ってしまうケースがおきており、問題になっています」と話す。
公平性は特に難しい。その理由として田中氏は「与える学習データが全て正しかった(教師付きデータ)としても、世の中で発生する全てのデータを与えることはできないからです。そもそも偏りがあるかどうかを判断するのは、主観や文化の差もあって非常に困難です」と説明する。
実際のビジネス現場では最終的な判断は人間が行うとしても、AIが示唆した結果が誰かに不利に働くとしたら社会問題に発展しかねない。
“シャドーAI”も課題に
また、田中氏がもう一つの課題としてあげるのは、企業でAIの導入が進むにつれ、“シャドーIT”ならぬ“シャドーAI”が問題になる可能性があることだ。
「企業内で複数のAIが導入されているケースもすでに数多く出てきています。AIの導入は情報システム部門ではなく、業務部門が主体となることが多く、社内に部門のAIが散在することになります。これを全社でどう管理していくかも今後重要になってくるでしょう」と田中氏は話す。
IBMでは早くから、こうしたAIの課題に着目し、2016年頃から研究や発表を重ねてきた。そして2018年9月、IBM Cloudで提供する新しいサービスのコンセプトとしてAIの信頼性を可視化する「Trust and Transparency capabilities」を発表した。2018年10月には、そのコンセプトをソフトウェアサービスとして具備する「AI OpenScale」を発表。現在はまだベータ版だが、年内には正式版になる予定だ。
AI OpenScaleの評価対象となるAIはIBM Watsonだけではない。複数のベンダーのAIを活用する時代が来ることを見据え、TensorFlow、Spark ML、AWS SageMaker、AzureMLなど多様な機械学習フレームワークに対応。また、ベースとなるツールはオープンソースで公開している。
ツールを活用し、複数のAIを可視化
田中氏はAI OpenScaleがどのように機能するか、画面を見せて解説してくれた。
図1は、自動車保険会社のAI OpenScale のダッシュボード画面のサンプルだ。
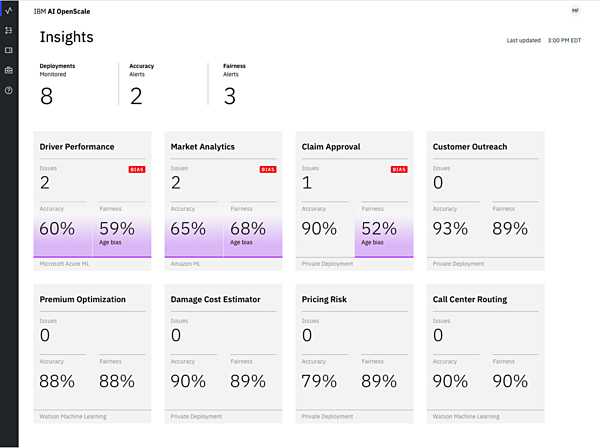
図1:AI OpenScaleのダッシュボード画面
現在8つのAIが社内に展開されており、そのうち3つのAIの「精度(Accuracy)」と6つのAIの「公平性(Fairness)」が芳しくないということが上部に示されている。その下に、それぞれのAIごとに精度と公平性のスコアが示されおり、一定のスコア以下だと色が変わって表示される。
例えば、自動車保険の申請を審査するためのAI「Claim Approval」は、精度が90%精度とおおよそ正しい答えを出せているものの、公平性は52%で何らかの対応が必要になっていることが一目瞭然に分かる。
精度や公平性が芳しくなければ、詳細を確認して改善する必要がある。詳細を知るためにAI OpenScaleでは、さまざまな視点でAIの精度や公平性についての確認ができる。例えば時系列でのスコア遷移を示すグラフを見て、スコアが大きく変動している日があったら、そこに何らかの問題があったと推測できる。
特定の項目を切り口に、AIの予測結果の分布を調べることも可能だ。図2は、自動車保険申請の審査における、年齢ごとの予測結果の分布を示している。
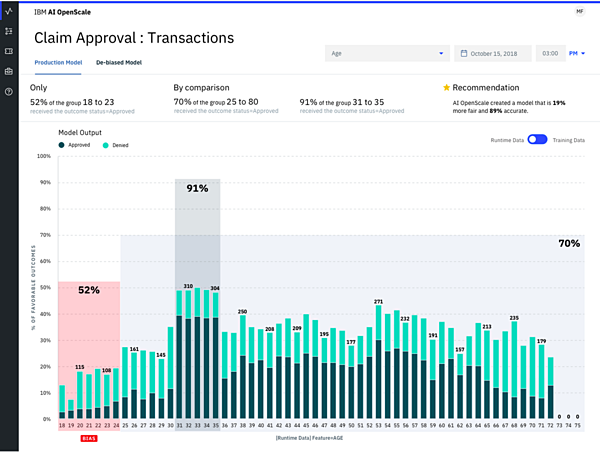
図2:年齢ごとの予測結果の分布
これを見ると、31-35歳は予測結果が92%なのに対して、18~24歳では52%となっている。すなわち、18〜24歳の申請を不認可と予測する割合が他の年齢層と比べてかなり高いということを意味しており、公平性に欠いている可能性を示唆している。
この示唆をもとに、AIの予測結果に偏りが発生した原因を究明していく。例えば、学習データの不足や偏りがあるか、AIモデルの構築アプローチに問題はないか、などを検証していくことになる。
さらにAI OpenScaleでは予測結果の根拠、つまり、AIがどの項目を重視して答えにつなげたのかを表示できる。図3は保険申請に対する審査で、AIが「認可90%」「不認可10%」判断したときの画面で、不認可の予測に強く影響した要素に「保険の適用期間」や「保険申請の頻度」があり、認可の予測に強く影響した要素に「個人加入」があることが示されている。AIがどの項目を判断の根拠にしているのか、AIの“思考”を可視化できるというわけだ。
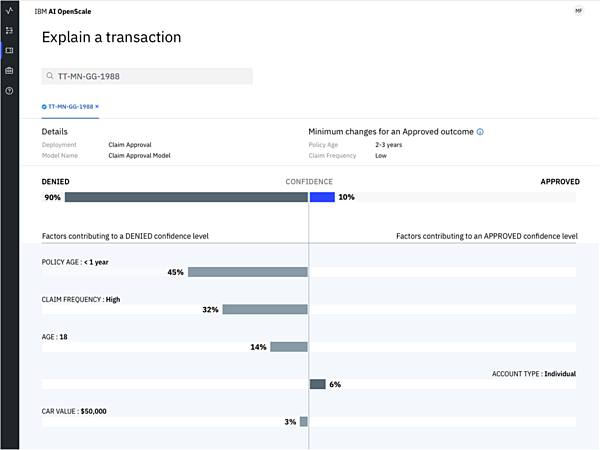
図3:予測の根拠を可視化
田中氏はAI OpenScaleについて「将来的には、可視化するだけではなく、どうすればよいのかを提言する機能も実装していく予定です」と話す。
例えば、モデルの作り方や与えるデータについて、どう改善すればいいのかを提案するといったことだ。
このようにAI OpenScaleは、AIの稼働状況における精度と公平性を可視化することで、AIが出す結果を評価するとともに、判断の根拠を説明可能にする。企業にAIが導入されるのが当たり前になりつつあるいま、AIのブラックボックス化を避け健全性を高めるうえで大きな力になりそうだ。
(取材:木村剛士、編集:真野祐樹、構成/撮影:加山恵美)
日本IBM | NewsPicks Brand Design

